В видеоролике ниже демонстрируется процесс развертывания решения Private AI Foundation с NVIDIA с использованием мастера быстрой настройки.
Автор пошагово показывает, как запустить Foundation Quick Start, выбрать проект и соответствующее пространство имен (namespace), а также вставить клиентский конфигурационный токен, полученный от NVIDIA. В примере используется среда с подключением к интернету, поэтому дополнительные параметры, такие как офлайн-реестр или изменение расположения драйверов, настраивать не требуется.
Далее в видео подробно рассматриваются ключевые параметры развертывания:
Выбор версии Kubernetes (или VKR).
Указание образа виртуальной машины для задач глубокого обучения (Deep Learning VM), заранее загруженного в библиотеку контента.
Выбор класса хранилища (storage class).
Настройка GPU-совместимых классов ВМ (резервирование GPU).
Выбор классов ВМ без поддержки GPU.
Также демонстрируется, что в рамках примера не активируются дополнительные сервисы VCF Data Services и не используется прокси-сервер.
После проверки всех параметров запускается процесс создания ресурсов каталога в выбранном пространстве имен. Через несколько минут новые элементы становятся доступны в разделе Build and Deploy -> Catalog, где можно увидеть созданные позиции Private AI Foundation с NVIDIA и при необходимости запросить их для дальнейшего использования.
Видео будет полезно администраторам и инженерам, занимающимся развертыванием инфраструктуры для задач искусственного интеллекта и машинного обучения в среде Kubernetes с поддержкой GPU.
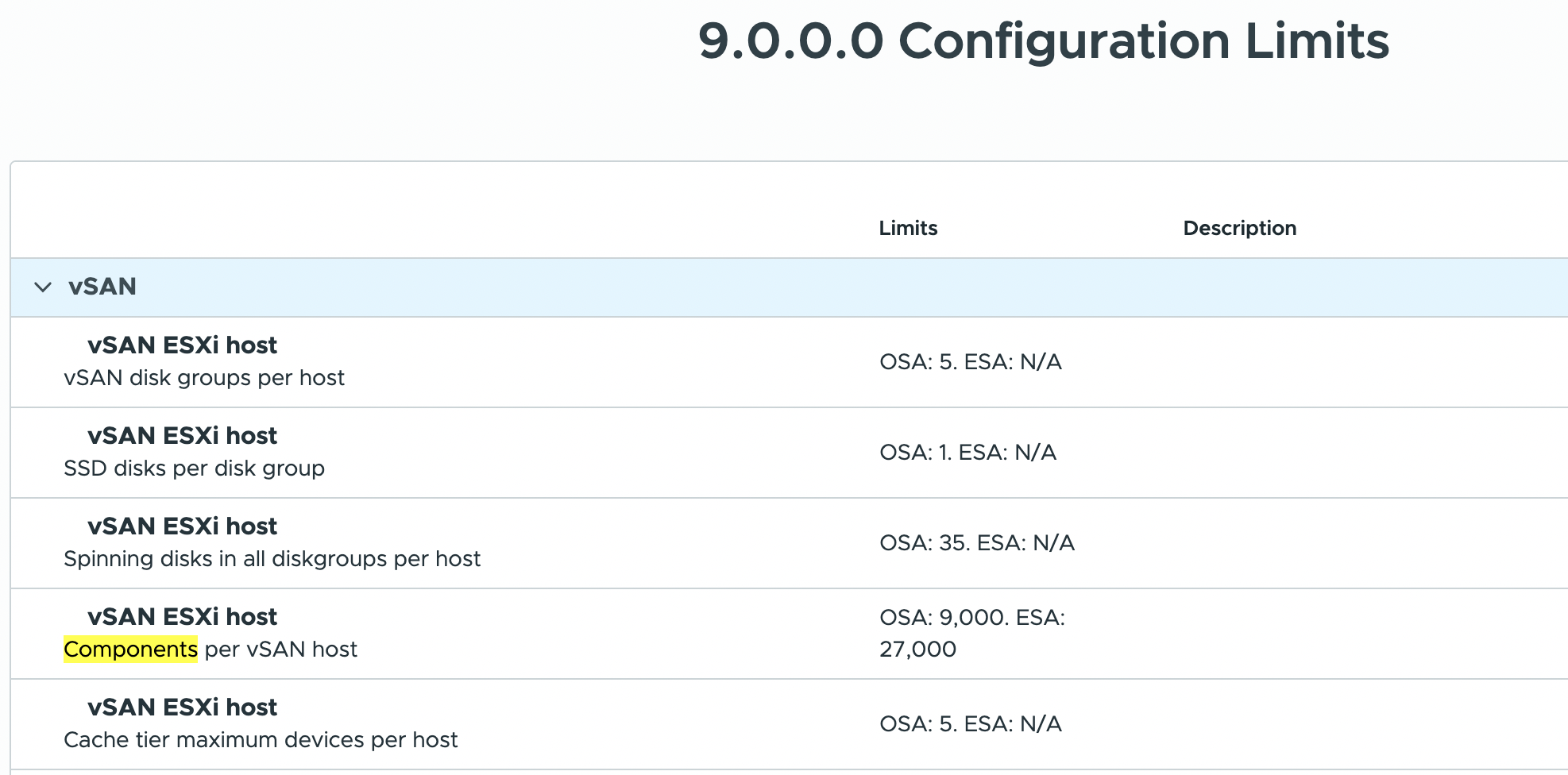
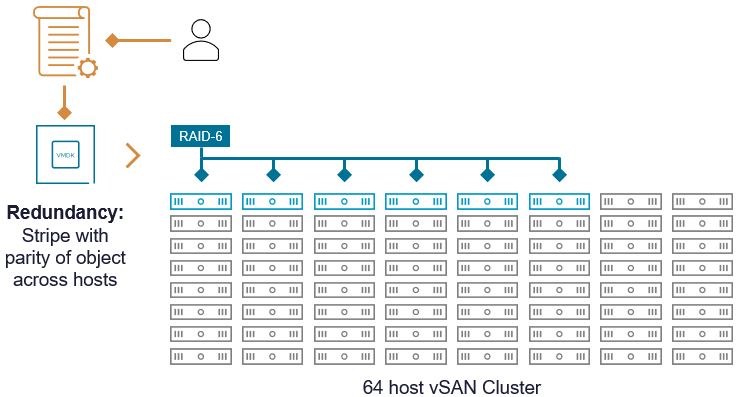
Дункан Эппинг написал интересный пост на тему решения VMware vSAN и допустимых лимитов на компоненты. За последние несколько лет у него было не так много обсуждений по поводу лимитов, но в последнее время такие разговоры почему-то стали возникать всё чаще. Если спросить клиента, каков лимит компонентов у vSAN, кто-то скажет — 9000 на хост (OSA), другие — 27 000 на хост (ESA), а некоторые даже знают ограничение по количеству компонентов на кластер (в документации эти лимиты указаны здесь и здесь). Однако есть один критически важный аспект, о котором большинство обычно не задумывается. В этом посте мы сосредоточимся на vSAN ESA.
Как уже упоминалось, существует лимит на хост и на кластер, но также есть ограничение на устройство (диск). Частая ошибка заключается в том, что люди воспринимают кластерный и хостовый лимиты как самостоятельные и фиксированные значения. Однако здесь есть зависимость. Как было сказано, у устройства тоже есть свой предел. В vSAN ESA одно устройство может содержать максимум 3000 data-компонентов и 3000 metadata-компонентов. Именно такие ограничения поддерживаются в текущей версии (vSAN 9.0). Пока сосредоточимся на data-компонентах (уровень ёмкости).
Это означает, что если в хосте 8 устройств или меньше, то максимальное количество компонентов будет не 27 000, а «количество устройств x 3000». Другими словами, если в хосте один NVMe-накопитель для vSAN ESA, максимальное количество компонентов для этого хоста — 3000. Если два устройства — максимум 6000, и так далее.
Почему об этом стоит писать? Если учесть количество компонентов на один объект и умножить его на типичное количество объектов, быстро становится понятно почему. Предположим, вы используете RAID-5 с ESA в конфигурации 4+1 — это даст как минимум 5 компонентов. Если у виртуальной машины несколько дисков, легко можно получить 35–40 компонентов на одну ВМ. Если взять лимит 3000 и разделить его, скажем, на 40 компонентов, получаем всего 75–80 виртуальных машин. Конечно, у вас будет несколько хостов, и это число масштабируется по их количеству, но пример наглядно показывает, почему важно учитывать этот максимум.
Возникает вопрос: почему эта тема стала подниматься именно сейчас? Дело в том, что по мере того как заказчики всё увереннее используют vSAN ESA, мы видим всё более «экзотические» конфигурации. Всё чаще развёртываются системы с очень ёмкими накопителями, но в небольшом количестве. Если раньше обычно использовали 6–8 устройств на хост по 1–2 ТБ каждое, то теперь всё чаще спрашивают о конфигурациях с одним NVMe-накопителем на 15 ТБ или двумя устройствами по 7.x ТБ. Нетрудно представить, что при таких вводных лимит в 3000 data-компонентов достигается значительно быстрее, чем хостовый лимит в 27 000 компонентов.
Поэтому, если вы планируете новый кластер vSAN, обязательно учитывайте эти ограничения. Не стоит думать только о ёмкости — есть и другие важные факторы, которые необходимо принимать во внимание.
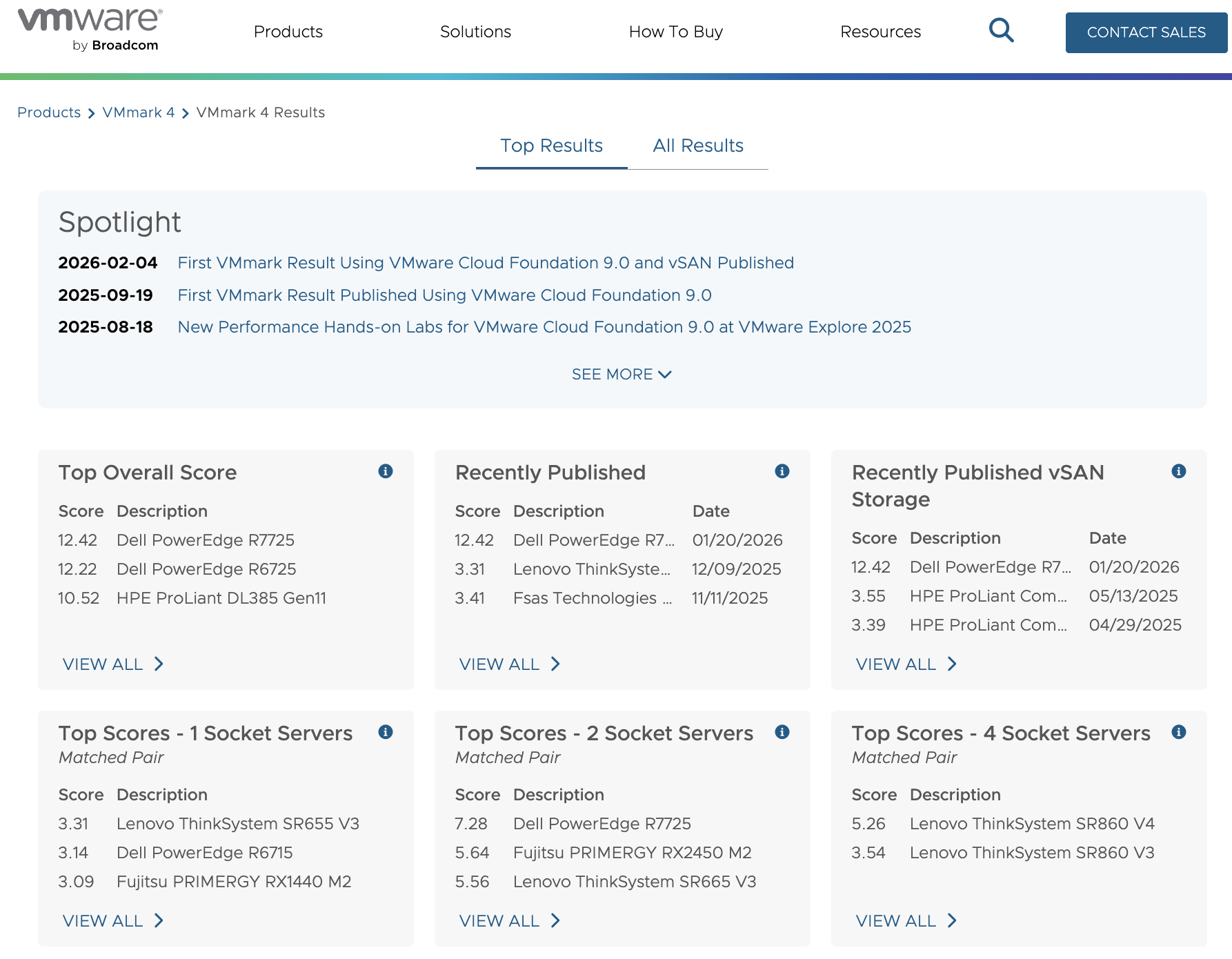
Компания VMware продолжает развитие своей платформы для частных облаков — VMware Cloud Foundation (VCF) 9.0. Недавно опубликованы первые результаты производительности с использованием бенчмарка VMmark 4, выполненные на базе VCF 9.0 с встроенным программно определяемым хранилищем VMware vSAN. Этот результат стал важной вехой для оценки возможностей платформы в реальных условиях нагрузки, демонстрируя, что VCF 9.0 способна эффективно масштабировать инфраструктуру частного облака с помощью современного оборудования и передовых технологий.
Что такое VMmark 4, и зачем он нужен
VMmark 4 — это кластерный бенчмарк VMware, предназначенный для измерения производительности и масштабируемости виртуализированных сред. В отличие от синтетических тестов, VMmark моделирует реальные корпоративные рабочие нагрузки:
базы данных
веб-серверы
почтовые системы
application-серверы
файловые сервисы
Нагрузка масштабируется в единицах tiles — каждый tile представляет собой комплекс виртуальных машин с типовым профилем предприятия. Итоговый показатель (VMmark Score) отражает способность кластера обслуживать увеличивающееся число рабочих нагрузок при сохранении SLA по производительности.
Тестовая конфигурация: ключевые компоненты
Для испытаний использовалась конфигурация, включающая новейшие аппаратные и программные компоненты:
Программное обеспечение: VMware Cloud Foundation 9.0.1.0 .
vSAN 9 ESA: программное хранилище уровня предприятия с оптимизированной архитектурой Express Storage Architecture.
NSX: сетевые сервисы и безопасность для виртуальной инфраструктуры.
Operations: мониторинг, аналитика и автоматизация облачных ресурсов.
Главная цель VCF — упростить развёртывание и управление частными облаками с уровня инфраструктуры до сервисов, при этом обеспечивая масштабируемость, производительность и возможность автоматизации.
Результат тестирования
Для объективного сравнения использовалась идентичная вычислительная платформа (AMD EPYC 9965, суммарно 1536 физических ядер кластера), но две разные подсистемы хранения:
vSAN 9.0 ESA (All-Flash, NVMe)
Классический FC SAN (Dell PowerMax 8000)
Таблица результатов:
Версия VCF
Тип хранилища
Процессор
Всего ядер
VMmark 4 Score
9.0.1.0
vSAN 9.0 ESA (All-Flash)
AMD EPYC 9965
1536
12.42 @ 15.4 tiles
9.0.0.0
FC SAN (Dell PowerMax 8000)
AMD EPYC 9965
1536
12.22 @ 14 tiles
Интерпретация результатов:
Tiles — это масштабируемые блоки нагрузки в VMmark 4. Каждый tile представляет набор типовых корпоративных рабочих нагрузок (Web, DB, Mail, Application Server и др.).
Значение 15.4 tiles означает более высокий уровень масштабирования кластера.
Итоговый показатель 12.42 — агрегированный производительный балл, учитывающий пропускную способность и latency.
Главный вывод - конфигурация с vSAN 9.0 ESA продемонстрировала:
Большее число поддерживаемых tiles (15.4 против 14 для FC)
Более высокий итоговый Score
Лучшую масштабируемость без использования внешнего SAN-массива.
Это подтверждает, что современная архитектура vSAN ESA в составе VCF 9.0 способна не только конкурировать с традиционными FC-решениями, но и превосходить их при одинаковой вычислительной базе.
Заключение
Новый VMmark 4 результат, полученный на VMware Cloud Foundation 9.0 с vSAN, подтверждает:
Высокую производительность и масштабируемость платформы.
Превосходство программно-определяемого хранения (vSAN) над традиционными SAN в современных конфигурациях.
Готовность VMware VCF 9.0 к использованию в масштабных частных облаках и корпоративных средах.
Для инженеров и архитекторов частных облаков это подтверждение того, что VCF 9.0 + vSAN — это не только удобная абстракция управления, но и мощная вычислительная платформа с высокими показателями эффективности.
Компания VMware выпустила обновлённое официальное руководство vSAN Stretched Cluster Guide, предназначенное для архитекторов и администраторов, работающих с растянутыми кластерами vSAN в рамках платформы VMware Cloud Foundation (VCF) 9.0. Документ был выпущен 18 февраля 2026 года и отражает актуальные практики проектирования, развертывания и эксплуатации таких инфраструктур.
Руководство подробно описывает ключевые концепции и требования к растянутым кластерам vSAN — типу конфигурации, в которой ресурсы распределены по двум географически разнесённым сайтам с целью обеспечения максимальной отказоустойчивости и непрерывной доступности виртуальных машин.
Что нового в версии для VCF 9.0
Актуализация под VCF 9.0 и vSAN 9
Документ ориентирован на использование растянутых кластеров именно в контексте VCF 9.0, в том числе с учётом последних архитектурных изменений и интеграции с инструментами автоматизации SDDC Manager.
Расширенные рекомендации по сетевым требованиям
В руководстве обновлены требования к сети между площадками — минимальные значения пропускной способности и задержек, оптимальные настройки MTU и рекомендации по сегментации трафика.
Поддержка разных архитектур хранения
Кроме классической архитектуры vSAN (OSA), руководство учитывает и vSAN Express Storage Architecture (ESA) — более современный вариант с улучшенной производительностью и эффективностью хранения.
Процессы установки и конвертации
Обозначены пошаговые процессы установки растянутого кластера, развёртывания и конфигурации vSAN Witness Host, а также инструкция по конвертации существующего кластера vSAN в растянутую конфигурацию без прерывания работы.
Сценарии отказов и восстановление
Отдельный раздел посвящён анализу отказов, поведения кластера в стрессовых ситуациях и практикам восстановления после отказов отдельных компонентов или целых площадок.
Практическая ценность для предприятий
Растянутые кластеры vSAN в VCF 9.0 остаются одним из ключевых решений для компаний с критичными требованиями к доступности (финансовые учреждения, телеком, здравоохранение), обеспечивая непрерывность бизнес-сервисов при отказах на уровне целого дата-центра.
Новый документ vSAN Stretched Cluster Guide служит исчерпывающим справочником для ИТ-специалистов, помогая спланировать архитектуру, соблюсти требования к оборудованию и сети, правильно настроить объектные политики хранения и обеспечить корректное поведение системы в случае сбоев.
По мере того как внедрение Kubernetes в корпоративной среде становится более зрелым, задачи, с которыми сталкиваются команды платформ, изменились. Развертывание кластеров больше не является основной проблемой. Настоящая работа начинается после первого дня: безопасное обновление кластеров, предсказуемая эксплуатация и поддержка нагрузок, таких как базы данных и регулируемые приложения, без хрупких скриптов или разовых исключений.
В последнем выпуске VMware vSphere Kubernetes Service (VKS) 3.6 в команде VMware сосредоточились именно на этих аспектах. Вместо того чтобы представлять длинный список несвязанных функций, этот релиз развивает платформу по нескольким ключевым операционным направлениям, которые действительно важны для платформенных инженеров и администраторов, запускающих Kubernetes в промышленной эксплуатации в крупном масштабе.
Кратко: что нового в VKS 3.6
VKS 3.6 включает улучшения в области корпоративной эксплуатации, производительности и гибкости экосистемы:
Открытая и расширяемая сетевая экосистема – поддерживаемый путь для партнерских сетевых дополнений позволяет плагинам Container Network Interface (CNI) нативно интегрироваться с VKS, оставаясь в рамках жизненного цикла и поддержки.
Настройка производительности для ресурсоемких по данным и чувствительных к задержкам нагрузок – декларативные профили TuneD позволяют безопасно настраивать параметры ядра и sysctl для баз данных и высокопроизводительных приложений без неподдерживаемых изменений на хостах.
Выбор корпоративной ОС с поддержкой RHEL – узлы на базе Red Hat Enterprise Linux (RHEL), включая кластеры со смешанными операционными системами.
Kubernetes 1.35, созданный для корпоративной эксплуатации
VKS 3.6 добавляет поддержку Kubernetes версии 1.35, продолжая обязательство Broadcom по предоставлению Kubernetes с сертификацией CNCF, предназначенного для корпоративного использования. Как и в предыдущих релизах, Broadcom предоставляет расширенную поддержку на 24 месяца для каждой версии Kubernetes с перекрывающейся поддержкой версий. Это позволяет крупным организациям переводить команды на новые версии в собственном темпе, не вынуждая выполнять массовые обновления всего парка или проводить сжатые окна обслуживания.
Некоторые заметные нововведения в выпуске Kubernetes 1.35 включают:
Настраиваемая параллельность для поэтапных обновлений StatefulSet с параметром maxUnavailable – теперь платформенные команды могут одновременно выводить из работы несколько Pod’ов во время обновлений StatefulSet, контролируя уровень нарушения работы для stateful-нагрузок и сокращая время развертывания.
Улучшенная осведомленность о топологии для нагрузок – приложения могут безопасно использовать информацию о топологии узлов, повышая понимание своего расположения в инфраструктуре, что полезно для чувствительных к задержкам и ресурсоемких по данным приложений.
Модернизированные основы хранения данных – такие усовершенствования, как тома на основе OCI, делают потребление хранилища в Kubernetes более согласованным с контейнерно-ориентированными моделями поставки.
В то же время Kubernetes продолжает удалять или объявлять устаревшими некоторые функции. VKS следует срокам устаревания upstream-версии, при этом предоставляя расширенную поддержку и четкие пути миграции, давая платформенным командам время на адаптацию без внезапных сбоев. Такой баланс сохраняет соответствие upstream-версии, избегая при этом разрушительных и массовых неожиданностей.
Более плавные обновления и более безопасные операции второго дня
Именно в процессе обновлений платформы Kubernetes чаще всего испытывают наибольшую нагрузку. На практике сбои при обновлении редко вызваны самим Kubernetes, а чаще конфигурацией и интеграциями. Политики, admission webhooks, а также инструменты безопасности или управления могут непреднамеренно блокировать операции жизненного цикла.
Развивая ранее внедренные предварительные проверки PodDisruptionBudget, VKS 3.6 расширяет проверки готовности к обновлению, чтобы выявлять распространенные конфликты конфигурации до начала обновления. Вместо обнаружения блокирующих факторов в середине процесса обновления платформенные команды могут заранее выявить и устранить проблемы до окна обслуживания, снижая количество неудачных обновлений и незапланированных сбоев. Эти проверки выполняются непрерывно, выявляя риски обновления через условие SystemCheckSucceeded, а не только во время выполнения обновления.
В результате — меньше неожиданностей при обновлении, более ранние предупреждения и более надежные операции второго дня без риска непредвиденной потери данных.
Производительность и ресурсоемкие по данным нагрузки
Запуск баз данных и других stateful-платформ в Kubernetes часто требует настройки ядра и параметров узлов, выходящих за пределы стандартных значений. Во многих средах команды полагались на ручные изменения узлов или специально собранные образы для удовлетворения этих требований. В моделях управляемого Kubernetes такие изменения, как правило, должны быть выражены декларативно (например, через утвержденные механизмы конфигурации, привилегированные DaemonSet’ы или стандартизированные образы), чтобы сохраняться при обновлениях и замене узлов.
VKS 3.6 вводит поддерживаемые профили TuneD, позволяя разработчикам декларативно настраивать ядро Linux (включая параметры sysctl и sysfs) через ресурсы Kubernetes. Профили могут быть привязаны к определенным пулам узлов, обеспечивая оптимизацию под конкретные нагрузки в рамках одного кластера.
Это делает распространенные сценарии простыми и поддерживаемыми, например:
Оптимизация узлов для высокопроизводительных сетевых нагрузок
Настройка поведения памяти для баз данных и систем кэширования
Корректировка параметров ядра для нагрузок, чувствительных к задержкам
Встроенный профиль обеспечивает безопасную отправную точку конфигурации, готовую для корпоративного использования, а пользовательские профили позволяют при необходимости сделать более глубокую специализацию. Результат — согласованная, безопасная при обновлениях настройка производительности, применяемая через стандартные рабочие процессы Kubernetes, без ручной конфигурации узлов и без дрейфа конфигурации.
Безопасность, соответствие требованиям и управление
VKS 3.6 упрощает поддержку нормативных и требований безопасности без жесткой фиксации кластеров в универсальных схемах усиленной защиты. Расширенная конфигурация компонентов Kubernetes позволяет платформенным командам настраивать уровень соответствия требованиям для каждой нагрузки и среды. Команды могут применять более строгие меры там, где это требуется, ослаблять их при необходимости и постепенно развивать конфигурации вместо пересоздания кластеров для изменения политики.
В этом выпуске также упрощено управление профилями AppArmor. Администраторы теперь могут определять профили AppArmor как Custom Resources и автоматически загружать их и поддерживать синхронизацию на всех рабочих узлах кластера или в отдельных пулах узлов. Это позволяет настраивать каждый workload с требуемым профилем AppArmor без сложности конфигурации на уровне узлов.
VKS 3.6 также повышает операционную автономность. Владельцы workload-кластеров теперь могут генерировать пакеты поддержки VKS без учетных данных vCenter, устраняя необходимость повышенного инфраструктурного доступа при устранении неполадок. Это снижает трения между командами Kubernetes и инфраструктуры, сохраняя принцип наименьших привилегий.
Пользовательский опыт платформы и развитие экосистемы
Корпоративные платформы Kubernetes требуют как сильных настроек по умолчанию, так и реального выбора в экосистеме. Чрезмерная жесткость замедляет внедрение; избыточная свобода создает операционные риски. Этот релиз продвигает баланс вперед, открывая платформу для партнерских инноваций и поддерживая возможность использования собственных инструментов заказчика.
Ваша сеть — ваш выбор
Теперь доступна поддерживаемая точка интеграции для сетевых партнеров и ISV. Платформенные команды могут использовать проверенные партнерами сетевые дополнения, оставаясь в рамках стандартных процессов жизненного цикла, обновления и поддержки. Это открывает возможности для нативной интеграции сторонних сетевых и сетевых защитных решений.
Команды могут сохранить сетевой стек, которому уже доверяют, а партнеры получают стабильную и поддерживаемую основу для разработки. Это снижает трения при миграции существующих сред Kubernetes на VKS и со временем расширяет набор доступных сетевых возможностей.
Ваш фаервол — ваш выбор
VKS 3.6 вводит централизованное управление правилами сетевого экрана на уровне узлов через API для всех поддерживаемых операционных систем. Теперь платформенные команды могут открывать необходимые порты для HostPorts и сервисов NodePort через конфигурацию кластера, вместо использования привилегированных init-контейнеров или DaemonSet’ов на каждом узле.
Перенос управления файрволом с отдельных нагрузок на уровень кластера упрощает конфигурацию, повышает аудируемость и снижает риски безопасности, связанные с привилегированными компонентами. Для Linux-узлов VKS 3.6 также добавляет поддержку backend nftables для kube-proxy, обеспечивая лучшую производительность и масштабируемость по сравнению с реализацией по умолчанию на основе iptables.
Ваша ОС — ваш выбор
Red Hat Enterprise Linux (RHEL) 9 присоединяется к Photon OS 5, Ubuntu 22.04 и 24.04, а также Windows Server 2022 в качестве поддерживаемых операционных систем для узлов кластера VKS. RHEL может использоваться как для узлов control plane, так и для рабочих узлов.
Для поддержки разнообразных требований приложений в рамках одного кластера VKS продолжает позволять различным пулам узлов работать на разных операционных системах. Пулы узлов RHEL могут существовать наряду с узлами Windows, Ubuntu и Photon, обеспечивая гетерогенные кластеры и постепенную миграцию ОС со временем.
VKS 3.6 также включает улучшенные инструменты для сборки пользовательских образов узлов для всех поддерживаемых операционных систем. Image Baker предназначен для сред с ограниченной сетевой связностью, работает независимо от vCenter для снижения инфраструктурных зависимостей и поставляется как плагин CLI VMware Cloud Foundation (VCF). Broadcom продолжает предоставлять готовые образы для Photon и Ubuntu.
Kubernetes — с меньшим количеством неожиданностей
Этот релиз сосредоточен на тех аспектах Kubernetes, которые наиболее важны после первого дня. Обновления становятся более предсказуемыми, настройка производительности для ресурсоемких нагрузок упрощается, среды на базе RHEL получают четкий путь миграции, а сетевая подсистема открывается для растущей экосистемы проверенных партнеров.
В совокупности эти изменения приводят Kubernetes в соответствие с тем, как заказчики реально используют его в промышленной эксплуатации: стандартизированно, с управлением на базе политик и с интеграцией с существующими инструментами и платформами.
Для платформенных команд, работающих в масштабе, результат прост: меньше неожиданностей, ниже операционные риски и более надежная основа для дальнейшего развития.
Более подробно о VMware vSphere Kubernetes Service 3.6 можно узнать на странице продукта.
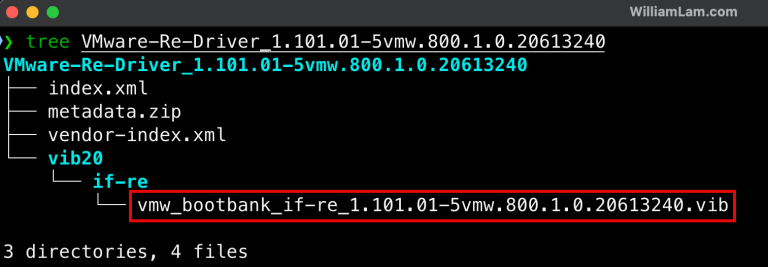
В 2026 году сообщество ESX получило сразу два важнейших обновления, которые расширяют возможности использования популярных сетевых устройств Realtek RTL8157 и RTL8156BG в виртуальной инфраструктуре VMware. Эти обновления особенно актуальны для лабораторных сред, мини-ПК и других систем с оборудованием, не поддерживаемым «из коробки» стандартным инсталлятором ESX.
Интеграция Realtek Network Driver Fling в бесплатный установочный ISO ESXi
Одной из ключевых проблем при установке ESXi 8 Update 3 на ПК с сетевыми адаптерами Realtek является отсутствие драйверов для этих сетевых контроллеров в стандартном установщике. Чтобы обойти это ограничение, было разработано решение для сообщества пользователей - Realtek Network Driver Fling (пока еще недоступно для ESX 9, но скоро будет).
Этот драйвер не является официальным продуктом Realtek, а представляет собой компонент Fling (экспериментальный инструмент для расширения ESXi), который обеспечивает базовую поддержку PCIe-сетевых адаптеров Realtek. Об этом недавно написал Вильям Лам.
Драйвер поддерживает ряд популярных моделей Realtek:
RTL8111 — 1 GbE
RTL8125 — 2,5 GbE
RTL8126 — 5 GbE
RTL8127 — 10 GbE
Проблема в том, что в бесплатных ISO-образах ESXi отсутствует пакет offline bundle (который можно было бы включить стандартным способом). Однако, как показано в одной из публикаций Вильяма Лама, можно вручную интегрировать драйвер в ISO-установщик ESXi 8.0 Update 3e.
Процесс включает:
Загрузку ISO-образа ESXi и архива драйвера Realtek Network Driver Fling.
Извлечение модуля драйвера и переименование в специальный файл (например, ifre.v00).
Добавление этого модуля в загрузочный конфигурационный файл ISO (boot.cfg) для автоматической загрузки при старте установщика.
Установку ESXi с загрузочного носителя и копирование модуля драйвера на установленную систему для постоянного использования.
Этот метод позволяет запускать ESXi даже там, где стандартный инсталлятор не видит сетевой адаптер — например, на небольших ПК или системах без Intel-сетевых контроллеров.
Расширение USB-сетевого драйвера — поддержка новых чипов Realtek
Другая важная новость касается USB Native Network Driver для ESXi, ещё одного модуля Fling, который добавляет поддержку USB-сетевых адаптеров. Сегодня этот драйвер поддерживает уже более 25 различных чипсетов, а в свежем обновлении разработчики добавили поддержку USB-адаптеров Realtek RTL8157 (5 GbE) и RTL8156BG (2,5 GbE).
Это означает, что пользователи могут подключать к ESXi внешние USB-сетевые адаптеры и использовать их для сетевого трафика без необходимости установки PCIe-карты. Такие адаптеры, особенно в формате USB-C или USB-A, часто используются в компактных рабочих станциях и ноутбуках.
Примеры совместимых устройств (которые можно использовать для тестов и сборок лабораторных систем):
USB-A - 2,5 GbE адаптер на базе RTL8156BG
USB-C - 5 GbE адаптер на базе RTL8157
Установка обновлённого USB-сетевого драйвера производится как с помощью offline bundle (через команду esxcli software component apply), так и путём интеграции в ISO-образ ESXi аналогично описанному в статье Вильяма процессу.
Почему это важно
До появления этих драйверов ESXi мог не видеть сетевые устройства Realtek, что делало невозможной установку гипервизора на недорогие системы или платформы с USB-адаптерами. Решения Fling активно развиваются сообществом и дают пользователям гибкие способы расширения функциональности ESXi без официальной поддержки от производителя.
Теперь вы можете:
Интегрировать новейший Realtek PCIe-драйвер прямо в установщик ESXi.
Использовать современные USB-сетевые адаптеры с высокими скоростями передачи (2,5 GbE и 5 GbE).
Поддерживать широкий спектр оборудования в лабораторных или домашних средах.
VMware недавно опубликовала обновлённый набор технических руководств, которые приводят рекомендации в соответствие с архитектурой эпохи VMware Cloud Foundation
и с новыми возможностями приложений Microsoft, включая SQL Server 2025 и Windows Server 2025.
Если вы планируете развёртывание VCF, модернизируете существующие среды, стандартизируете платформу, обновляете парк SQL Server или модернизируете инфраструктуру идентификации, мы рекомендуем ознакомиться с этими документами до того, как будет окончательно утверждён ваш следующий дизайн-воркшоп, цикл закупок или план миграции.
Руководство 1: Проектирование Microsoft SQL Server на VMware Cloud Foundation
Для многих команд решение о виртуализации SQL Server уже принято. Как говорится в руководстве: «вопрос больше не в том, виртуализировать ли SQL Server, а в том, как…». И это «как» существенно изменилось в мире VCF. Платформа стала более регламентированной, операционная модель — более стандартизированной, а поддерживающие возможности (хранилище, сеть, управление жизненным циклом, безопасность) эволюционировали с учётом развития аппаратных возможностей и операционных методик.
Обновлённое руководство предназначено для читателей, которые уже понимают как VCF, так и SQL Server. Оно ориентировано на несколько ролей: архитекторов, инженеров/администраторов и DBA.
Несколько моментов, на которые стоит обратить внимание:
Современные рекомендации по CPU и NUMA теперь учитывают и новое поведение топологии в эпоху VCF. Руководство рассматривает «новые параметры конфигурации топологии vNUMA в VMware Cloud Foundation (VCF)» и объясняет, почему это поведение важно для крупных виртуальных машин SQL Server.
Чёткая и обновлённая позиция по CPU hot plug в эпоху SQL Server 2025. В руководстве прямо указано: CPU Hot-Add больше не поддерживается в SQL Server 2025, и его не следует включать на таких виртуальных машинах.
Рекомендации по хранилищу, соответствующие направлению развития VCF. Если вы оцениваете архитектурные варианты vSAN, руководство объясняет, почему vSAN Express Storage Architecture (ESA) привлекателен для заказчиков, переходящих на более современное оборудование, и подчёркивает возможности эффективности ESA, такие как глобальная дедупликация и преимущества сжатия для нагрузок баз данных.
Пояснения по устаревающим функциям, влияющим на долгоживущие архитектуры. Если в вашей текущей архитектуре активно используются vVols, учтите, что Virtual Volumes объявлены устаревшими, начиная с VCF 9.0 и VMware vSphere Foundation 9.0 (полный отказ запланирован в будущих релизах).
Операционная реалистичность для мобильности и обслуживания. Руководство рассматривает использование multi-NIC vMotion для снижения риска зависания (stun) при миграции крупных, потребляющих много памяти виртуальных машин SQL, а также отмечает, что VCF внедряет vMotion Notifications, чтобы помочь чувствительным к задержкам и кластер-осведомлённым приложениям безопаснее обрабатывать миграции.
Если вы принимаете решения - это тот документ, который снижает объём переработок, вызванных неожиданностями. Если вы технический специалист - это тот документ, который не позволит вам унаследовать архитектуру в стиле «it depends», которая позже приведёт к простою.
Руководство 2: Проектирование Microsoft SQL Server для высокой доступности на VMware Cloud Foundation
Второе руководство сосредоточено там, где ставки особенно высоки: корректное проектирование доступности SQL Server на VCF без смешивания устаревших предположений, неподдерживаемых конфигураций или подхода «потом исправим» в кластеризации.
Оно написано для смешанной аудитории, включая DBA, администраторов VMware, архитекторов и IT-руководителей. И в нём ясно указано, что «доступность» — это не функция, которую добавляют в конце; выбранная модель защиты должна определяться бизнес-требованиями.
Несколько особенно практичных обновлений:
Реалии доступности SQL Server 2025, чётко сопоставленные с механизмами защиты. Руководство связывает уровни защиты с современными возможностями обеспечения доступности SQL Server, подчёркивает области, где SQL Server 2025 усиливает архитектуры на базе Availability Groups (AG), и отмечает, что Database Mirroring удалён в SQL Server 2025.
Рекомендации по согласованию жизненного цикла, которые действительно важны для IT-руководства. Начиная с SQL Server 2025, отмечается, что более старые версии Windows Server вышли из основной поддержки, и рекомендуется использовать Windows Server 2025 или Windows Server 2022 при наличии совместимости — прямой переход к поддерживаемым и обоснованным платформам.
Современные варианты кластеризации с общими дисками без навязывания устаревших архитектур. Руководство указывает, что в средах эпохи VCF 9 семантика общих дисков для FCI может быть реализована современными способами — подчёркивается использование Clustered VMDKs и явно обозначается движение в сторону отказа от устаревших зависимостей.
Рекомендации по DRS anti-affinity, предотвращающие «самоорганизованные» события HA. Если узлы кластера SQL работают на одном и том же хосте ESXi «потому что так решил DRS», это не высокая доступность, а отложенный инцидент. Настройте соответствующие правила DRS, чтобы узлы кластера были физически разделены.
Требования к vMotion Application Notification, изложенные подробно. Руководство описывает использование уведомлений приложений, включая требования, такие как актуальные VMware Tools и рекомендуемая настройка таймаутов — именно те детали, которые команды часто выясняют в условиях уже упавшей системы.
Рекомендации по vSAN ESA, отражающие текущие возможности. Указывается направление политик ESA и отмечается глобальная дедупликация (впервые представленная в VCF 9.0) как рекомендуемая для определённых сценариев Availability Group SQL Server в пределах одного кластера vSAN.
Это то руководство, которое вы передаёте команде, когда бизнес говорит: «нам нужна более высокая доступность», — и вы хотите, чтобы ответом стало инженерно проработанное решение.
Руководство 3: Виртуализация служб домена Active Directory на VMware Cloud Foundation
Active Directory (AD) Domain Services (DS) — одна из тех служб, о которых не думают до тех пор, пока всё не перестанет работать. Обновлённое руководство по AD DS прямо признаёт это, указывая, что многие организации справедливо рассматривают AD DS как по-настоящему критичное для бизнеса приложение, поскольку аутентификация, доступ к ресурсам и бесчисленные рабочие процессы зависят от него.
Оно также напрямую обращается к сохраняющемуся рефлексу «физического контроллера домена». Благодаря развитию Windows Server и зрелым практикам VCF, в руководстве говорится, что эти улучшения теперь позволяют организациям «безопасно виртуализировать сто процентов своей инфраструктуры AD DS».
Существенно обновлены не общие рекомендации «виртуализируйте это», а современный набор функций и механизмов защиты, которые меняют подход к проектированию и защите виртуальных контроллеров домена:
В руководстве указано, что лишь несколько усовершенствований существенно изменяют прежние рекомендации, включая Virtualization-Based Security (VBS), Secure Boot, шифрование на уровне виртуальной машины и улучшенную синхронизацию времени в гостевых ВМ — и эти изменения учтены там, где это необходимо.
Документ явно ориентирован на несколько аудиторий (архитекторов, инженеров/администраторов и руководителей/владельцев процессов), что важно для AD DS, поскольку проектирование и эксплуатация неразделимы.
Подчёркиваются операционные меры защиты при восстановлении после сбоев. Например, рекомендуется использовать приоритет перезапуска ВМ в vSphere HA, чтобы ключевые инфраструктурные службы запускались раньше после аварийного восстановления.
Подробно рассматриваются механизмы обеспечения целостности в эпоху виртуализации (например, поведение VM-Generation ID), созданные специально для устранения исторических опасений, связанных со снапшотами и откатами.
Если вы модернизируете инфраструктуру идентификации, консолидируете датацентры или строите частное облако на базе VCF с сильной позицией по безопасности, этот документ обязателен к прочтению. AD DS — это не просто ещё одна рабочая нагрузка. Это сущность, от которой зависит работа всего вашего стека.
Руководство 4: Запуск Microsoft SQL Server Failover Cluster Instance на VMware vSAN платформы VMware Cloud Foundation 9
Если ваша модель обеспечения доступности по-прежнему основана на кластеризации с общими дисками — будь то из-за ограничений приложений, операционных предпочтений или необходимости сохранить модель SQL Server FCI — это руководство является практическим дополнением «как это реально работает на VCF 9» к более общим рекомендациям по HA. Это эталонная архитектура для запуска Microsoft SQL Server Failover Cluster Instance (FCI) с использованием общих дисков на базе vSAN, валидированная как для стандартного кластера vSAN, так и для сценария растянутого кластера vSAN.
Несколько моментов, на которые стоит обратить внимание:
Нативная поддержка WSFC + общих дисков на vSAN (с подробным описанием механики). В VCF 9 «vSAN обеспечивает нативную поддержку виртуализированных Windows Server Failover Clusters (WSFC)» и «поддерживает SCSI-3 Persistent Reservations (SCSI3PR) на уровне виртуального диска» — ключевое требование для арбитража общих дисков в WSFC.
Две настройки конфигурации, от которых зависит работоспособность общих дисков. Указывается, что общие диски должны быть подключены к контроллеру с параметром SCSI Bus Sharing, установленным в Physical, и что «режим диска для всех дисков в кластере должен быть установлен в Independent – Persistent», чтобы избежать неподдерживаемой семантики снапшотов на общих дисках.
Операционные особенности растянутого кластера: задержки, размещение и кворум являются частью архитектуры. Рекомендуется «менее четырёх миллисекунд межсайтовой (round trip) задержки» для SQL-баз данных уровня tier-1 в растянутых кластерах vSAN, а также подчёркивается необходимость правил DRS VM/Host для разделения узлов WSFC по разным хостам.
Также рекомендуется использовать диск-свидетель кворума, чтобы растянутый кластер сохранял доступность witness-диска при отказе сайта без остановки службы кластера FCI.
Практический путь миграции с SAN pRDM на общие VMDK vSAN. С самого начала подчёркивается: «перед миграцией настоятельно рекомендуется создать резервную копию», и отмечается, что миграция выполняется офлайн. Описываются шаги по остановке роли кластера, выключению узлов и использованию Storage Migration для преобразования pRDM в VMDK на vSAN ± с обходным решением через PowerCLI (включая пример кода) в случае, если выбор формата диска в мастере Migrate недоступен.
Это руководство, которое вы передаёте команде, когда требование звучит как «нам нужна семантика FCI», и вы хотите получить осознанную, поддерживаемую архитектуру.
Что дальше
Если вы активно проектируете, обновляете или мигрируете инфраструктуру, рассматривайте эти руководства в контексте команд:
Команды платформы: сначала прочитайте руководство по SQL Server, чтобы согласовать значения по умолчанию вычислений/хранилища/сети с поведением SQL.
DBA и инженеры инфраструктуры: прочитайте руководство по HA до того, как зафиксируете модель кластеризации, стратегию хранения и модель обслуживания.
Команды по идентификации и безопасности: прочитайте руководство по AD DS, чтобы согласовать меры настройки, восстановления и операционные процессы с современными механизмами защиты виртуализации.
Команды, использующие (или стандартизирующие) SQL Server FCI: прочитайте руководство по FCI на vSAN, чтобы зафиксировать требования к общим дискам, позицию по политике хранения и ограничения растянутого кластера до внедрения.
Ниже приведены прямые ссылки для скачивания упомянутых документов:
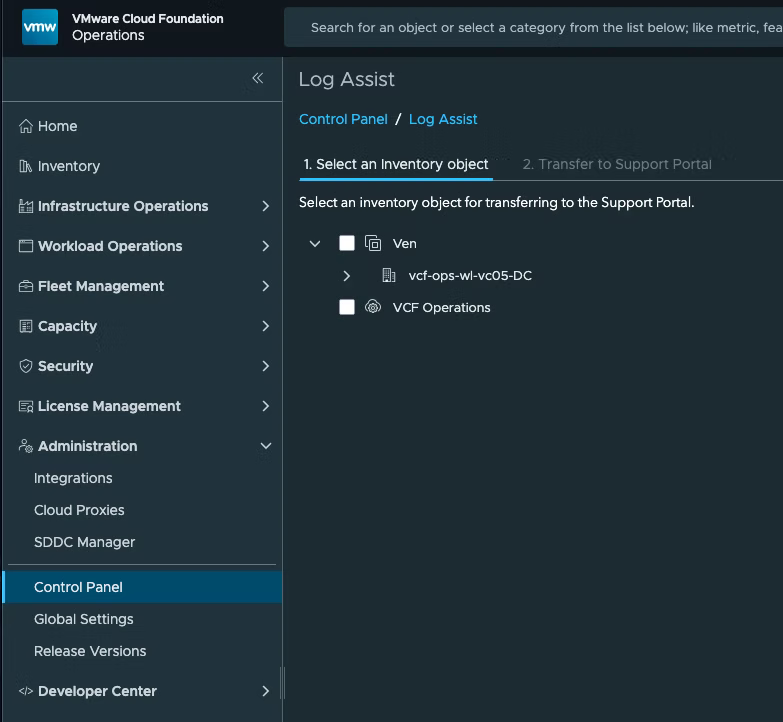
В современных гибридных и частных облаках большое количество данных о состоянии систем поступает из самых разных источников: систем резервного копирования, хранилищ данных, SaaS-платформ и внешних сервисов. Однако интеграция этих данных в единую платформу мониторинга часто оказывается сложной задачей. Для решения этой проблемы в составе VMware Cloud Foundation был представлен инструмент Management Pack Builder (MPB), предназначенный для расширения наблюдаемости и видимости инфраструктуры. О его бета-версии мы писали еще в 2022 году, но сейчас он уже полноценно доступен в составе VCF.
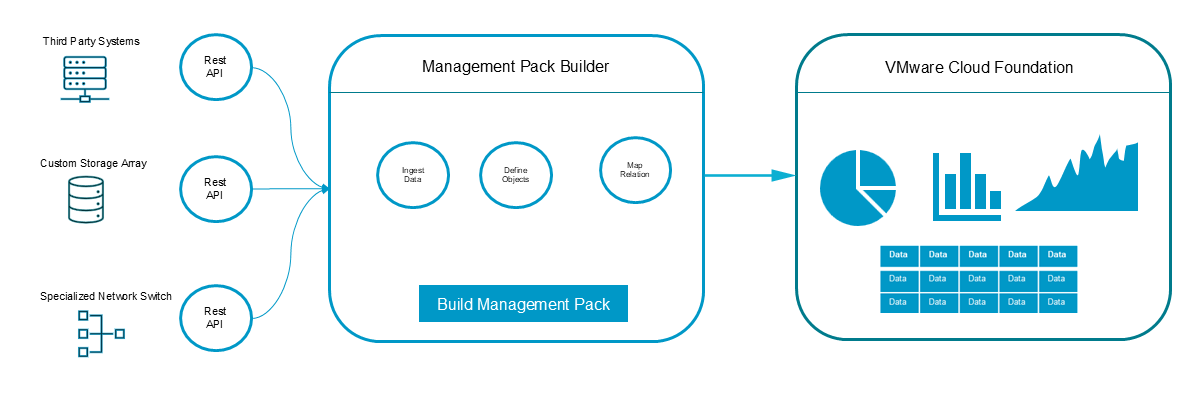
Что такое Management Pack Builder
Management Pack Builder (MPB) — это функциональность VMware Cloud Foundation, представляющая собой no-code-решение для создания пакетов управления (management packs), которые позволяют импортировать данные наблюдения из внешних источников в систему мониторинга VCF Operations. MPB выполняет роль промежуточного слоя, преобразуя данные, полученные через REST API сторонних систем, в объекты, метрики, свойства и события, понятные и используемые в экосистеме VMware Cloud Foundation.
С помощью Management Pack Builder можно:
Подключаться к REST API внешних систем
Создавать собственные типы объектов мониторинга
Сопоставлять данные API с метриками и свойствами в VCF Operations
Формировать повторно используемые пакеты управления для развертывания в разных средах
Какие задачи решает Management Pack Builder
Заполнение пробелов в мониторинге
Во многих организациях используются системы, для которых не существует готовых адаптеров мониторинга VMware. MPB позволяет интегрировать такие источники данных и устранить «слепые зоны» в наблюдаемости инфраструктуры.
Упрощение интеграции сторонних решений
Традиционная разработка адаптеров требует значительных затрат времени и ресурсов. Management Pack Builder позволяет создавать интеграции без написания кода, что существенно ускоряет процесс и снижает операционные издержки.
Централизация данных наблюдаемости
MPB помогает устранить разрозненность данных, объединяя телеметрию из различных систем в единой платформе. Это упрощает корреляцию событий, ускоряет диагностику проблем и снижает среднее время восстановления сервисов.
Масштабируемость и повторное использование
Один раз созданный пакет управления может быть экспортирован и развернут в других инсталляциях VMware Cloud Foundation, обеспечивая единый подход к мониторингу в масштабах всей организации.
Работа с нестандартными API
Management Pack Builder поддерживает гибкое сопоставление данных и может использоваться даже в случаях, когда REST API внешних систем не полностью соответствует стандартным спецификациям.
Преимущества использования MPB
Использование Management Pack Builder обеспечивает следующие преимущества:
Быстрое подключение новых источников телеметрии
Единая панель мониторинга в рамках VMware Cloud Foundation
Снижение затрат на разработку и поддержку интеграций
Возможность моделирования пользовательских объектов и метрик
Простое распространение решений между средами
Типовой рабочий процесс в Management Pack Builder
Процесс создания пакета управления с помощью MPB включает следующие этапы:
Определение источника данных и необходимых конечных точек API
Проектирование объектной модели и связей между объектами
Настройка параметров сбора данных, включая аутентификацию и расписание
Сопоставление полей ответов API с метриками и свойствами
Тестирование корректности сбора и отображения данных
Экспорт и развертывание пакета управления в других средах
Пример использования: мониторинг задач резервного копирования
Предположим, что система резервного копирования предоставляет данные о заданиях через REST API, включая статус выполнения, продолжительность и объем обработанных данных. С помощью Management Pack Builder можно:
Подключиться к API системы резервного копирования
Создать новый тип объекта, представляющий задачу резервного копирования
Определить метрики, отражающие состояние и эффективность выполнения
Настроить дашборды и оповещения в VCF Operations
Использовать созданный пакет управления в других кластерах
Данный процесс на примере решения Rubrik показан в видео ниже:
В результате информация о резервном копировании становится частью единой системы наблюдаемости VMware Cloud Foundation, и вам не потребуется никаких отдельных консолей для мониторинга этого процесса.
Рекомендации по эффективному использованию MPB
Для успешного применения Management Pack Builder рекомендуется:
Начинать с минимального набора метрик и постепенно расширять модель
Использовать стабильные и уникальные идентификаторы объектов
Оптимизировать частоту опроса API, чтобы избежать избыточной нагрузки
Использовать примеры и лучшие практики, опубликованные в сообществах VMware
Роль Management Pack Builder в экосистеме VMware Cloud Foundation
VMware Cloud Foundation ориентирован на обеспечение унифицированного управления, операций и наблюдаемости в гибридных и частных облаках. Management Pack Builder дополняет эту концепцию, позволяя включать в контур мониторинга любые внешние и пользовательские системы.
Это обеспечивает целостное представление о состоянии инфраструктуры и приложений, независимо от источника данных.
Заключение
Management Pack Builder является важным инструментом для расширения возможностей наблюдаемости в VMware Cloud Foundation. Он позволяет быстро и гибко интегрировать сторонние источники телеметрии, сократить затраты на разработку адаптеров и централизовать мониторинг.
Использование MPB помогает организациям получить полную и целостную картину состояния своей инфраструктуры, повышая надежность и управляемость IT-среды.
Отличные новости для сетевых инженеров и архитекторов, работающих в экосистеме VMware. Компания представила новую сертификацию VMware Certified Advanced Professional – VCAP Administrator Networking (3V0-25.25). Этот экзамен продвинутого уровня (VCAP) предназначен для подтверждения глубоких знаний и практических навыков в проектировании, развертывании и администрировании сетевых решений VMware Cloud Foundation (VCF).
Новый стандарт профессиональной экспертизы в VCF Networking
Экзамен 3V0-25.25 ориентирован на опытных ИТ-специалистов, которые работают с современными корпоративными и мультиоблачными инфраструктурами. Получение данной сертификации демонстрирует способность кандидата эффективно решать сложные сетевые задачи в рамках архитектуры VMware Cloud Foundation.
Ключевые параметры экзамена:
Код экзамена: 3V0-25.25
Продолжительность: 135 минут
Количество вопросов: 60
Проходной балл: 300
Стоимость: 250 USD
Язык: английский
Кому подойдет эта сертификация
Экзамен рассчитан на специалистов с уверенным опытом в корпоративных сетях и экспертизой по решению VMware NSX. Рекомендуемый профиль кандидата включает:
1–2 года практического опыта проектирования и администрирования решений NSX
Не менее 2 лет работы с Enterprise-сетями
Уверенное владение UI-, CLI- и API-ориентированными рабочими процессами VCF
Практический опыт работы с VCF Networking и vSphere
Если вы ежедневно сталкиваетесь с проектированием и эксплуатацией сложных сетевых архитектур, этот экзамен станет логичным шагом в развитии карьеры.
Что проверяет экзамен 3V0-25.25
Основной акцент в экзамене сделан на планирование и дизайн сетевых решений VCF, с максимальной ориентацией на реальные архитектурные сценарии. Ключевые области оценки знаний включают:
ИТ-архитектуры, технологии и стандарты - проверяется понимание архитектурных принципов, умение различать бизнес- и технические требования, а также управлять рисками и ограничениями при проектировании.
Планирование и проектирование решений VMware - центральный блок экзамена, оценивающий способность спроектировать полноценное решение VMware Cloud Foundation с учетом доступности, управляемости, производительности, безопасности и восстановляемости.
Несмотря на то что в экзаменационном гайде указано наличие разделов без активных проверяемых целей, глубокое понимание всего жизненного цикла VCF Networking — от установки до устранения неполадок — значительно повышает шансы на успех.
Как подготовиться к экзамену
VMware рекомендует сочетать практический опыт с целенаправленным обучением. Для подготовки к экзамену доступны следующие курсы:
VMware Cloud Foundation Networking Advanced Design
VMware Cloud Foundation Networking Advanced Configuration
VMware Cloud Foundation Networking Advanced Troubleshooting
Также крайне важно изучить официальную документацию VMware Cloud Foundation 9.0, актуальные release notes и технические материалы от Broadcom, чтобы быть в курсе всех возможностей и изменений платформы.
Будьте среди первых сертифицированных специалистов
Выход сертификации VMware Certified Advanced Professional – VCF Networking — значимое событие для профессионалов в области сетевых технологий. Этот статус подтверждает высокий уровень экспертизы и позволяет выделиться на фоне других специалистов, открывая новые карьерные возможности. Если вы хотите быть на передовой в индустрии и официально подтвердить свои знания в области VCF Networking — сейчас самое время сделать этот шаг.
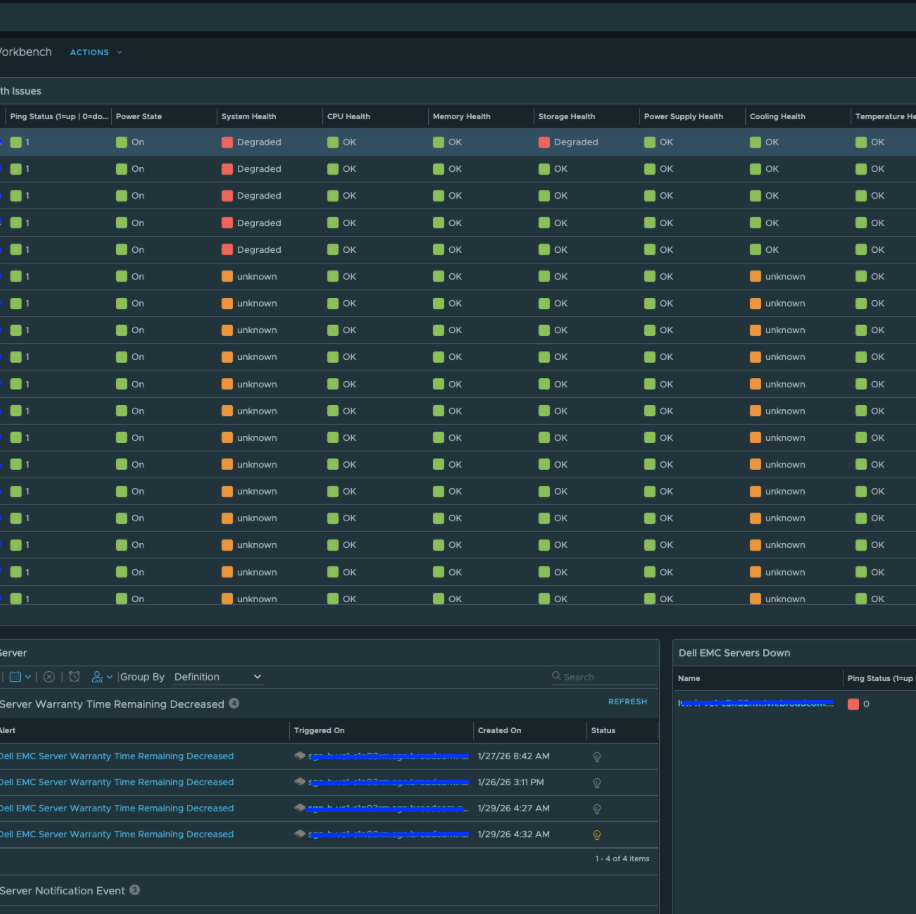
Недавно был выпущен пакет управления vCommunity Management Pack для VCF Operations (подробнее о нем - тут), который охватывает несколько сценариев использования, включая: расширенные системные настройки хоста ESX, его пакеты и лицензирование, статус сетевых интерфейсов (NIC), расширенные параметры виртуальных машин, параметры ВМ, типы контроллеров SCSI виртуальных машин, а также службы события Windows.
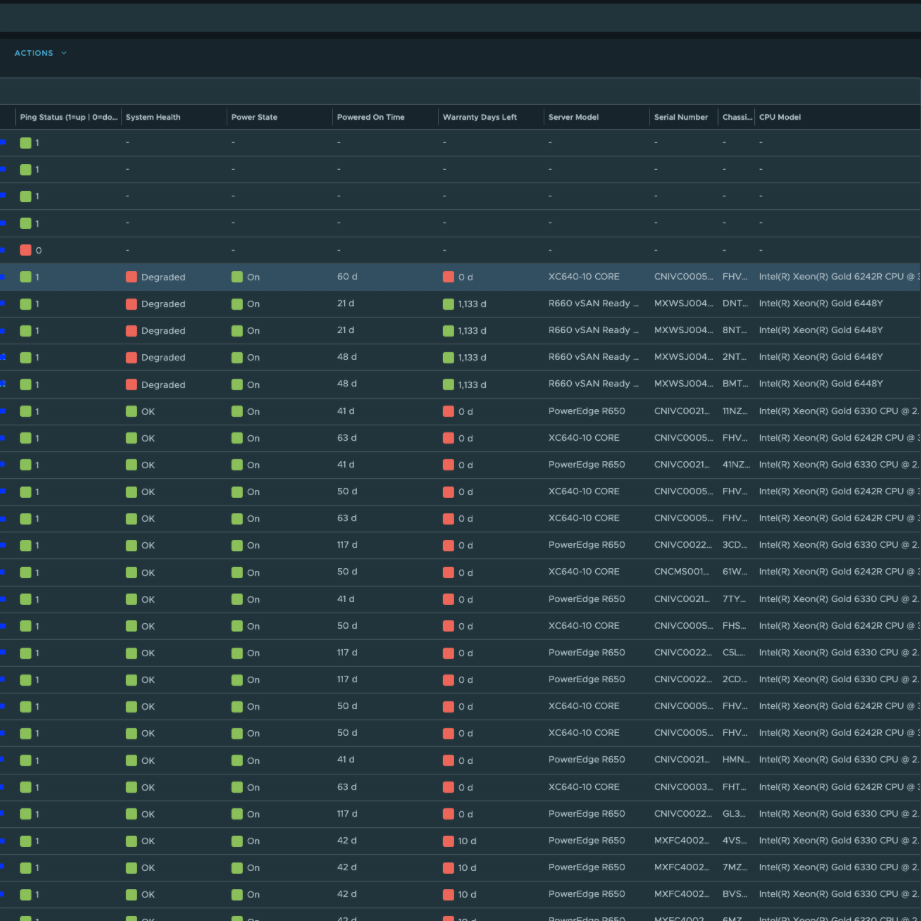
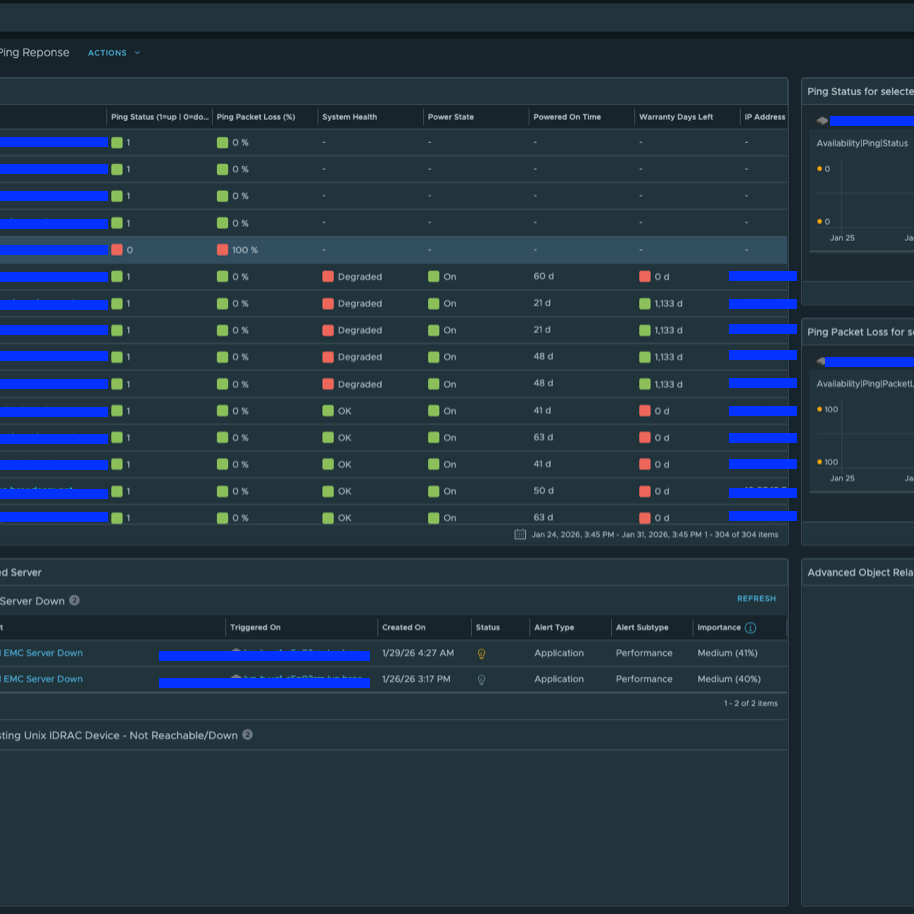
Ну а на днях стал доступен для скачивания проект Hardware vCommunity Management Pack для VCF Operations, разрабатываемый инженером Broadcom Онуром Ювсевеном. Начальная версия поддерживает серверы Dell EMC PowerEdge (с использованием Redfish API на iDRAC). Он собирает десятки метрик, свойств и событий. Пакет управления включает 5 дашбордов, 8 представлений, 14 алертов и 19 симптомов (symptoms). Дашборды выглядят следующим образом.
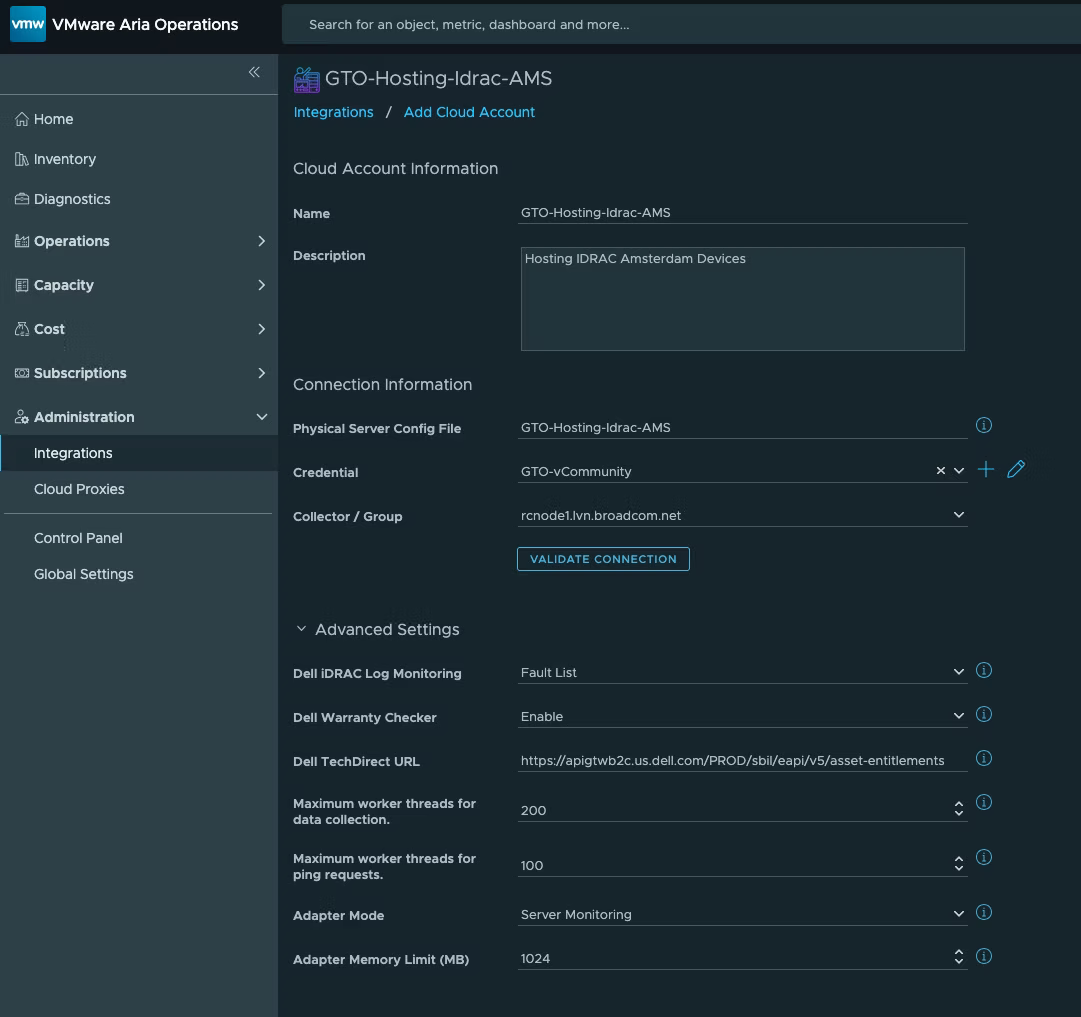
Сам Management Pack можно скачать здесь. После загрузки он устанавливается так же, как и любой другой Management Pack. Затем необходимо создать экземпляр адаптера (или несколько, если требуется), который будет выглядеть примерно следующим образом.
Существует несколько требований:
Файл конфигурации физических серверов — список FQDN/IP-адресов серверов Dell EMC. Файлы конфигурации можно создать в разделе Operations > Configurations > Management Pack Configurations > User Defined. Формат должен быть вот таким.
Учётные данные iDRAC Redfish API (только чтение), а также Dell TechDirect Client ID/Secret (если требуется информация о гарантии).
Collector/Group — необходимо использовать Cloud Proxy.
Dell iDRAC Log Monitoring — уровень событий iDRAC, которые вы хотите собирать (или Disabled, если сбор не нужен).
Dell TechDirect URL — URL Dell TechDirect, к которому экземпляр адаптера будет обращаться для получения информации о гарантии.
Maximum worker threads for data collection — максимальное количество рабочих потоков для сбора данных (по умолчанию 200).
Maximum worker threads for ping request — максимальное количество рабочих потоков для ping-запросов (по умолчанию 100).
Adapter Mode — режим работы адаптера: Server Monitoring или PING Only.
Adapter Memory Limit (MB) — максимальный объём памяти, который будет использовать экземпляр адаптера.
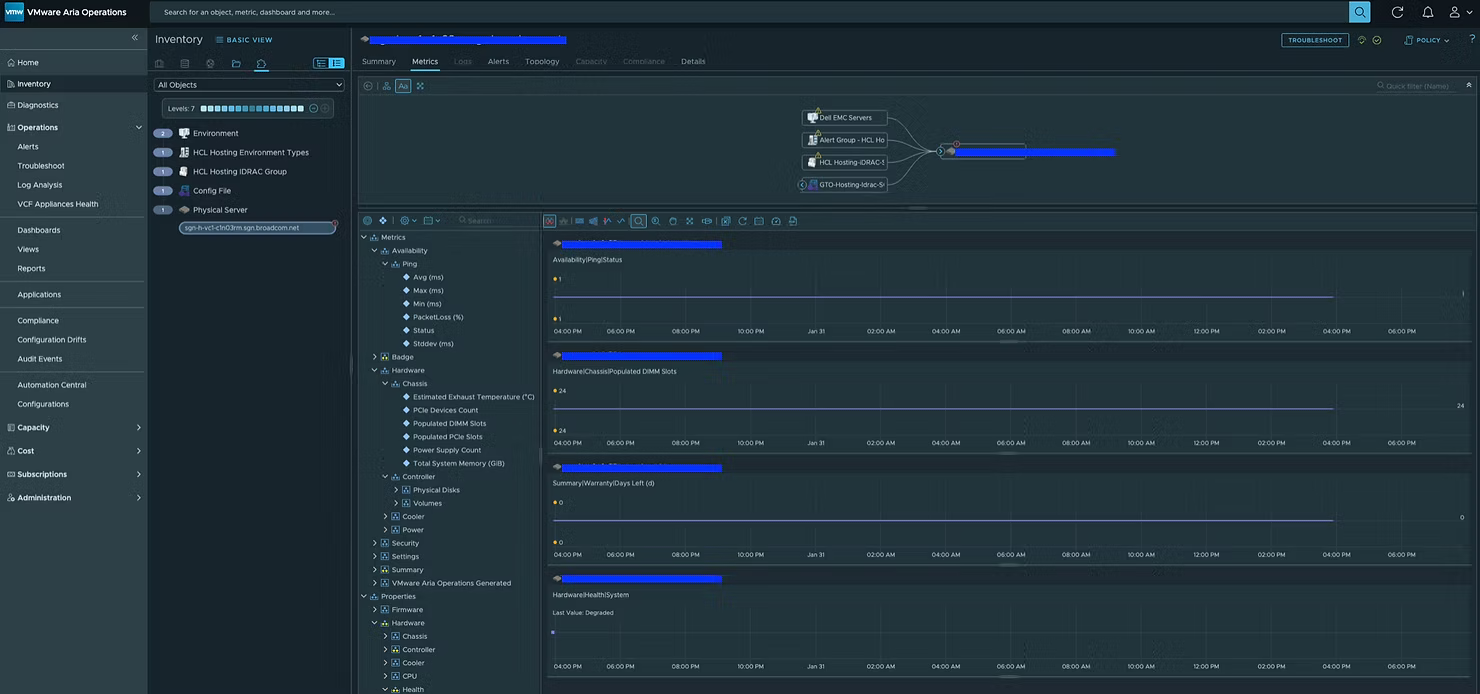
После установки назначьте Custom Group Dell EMC Servers политике Hardware vCommunity Policy. Это включит все определения оповещений. vCommunity Management Pack создаст новый тип объекта с именем Physical Server.
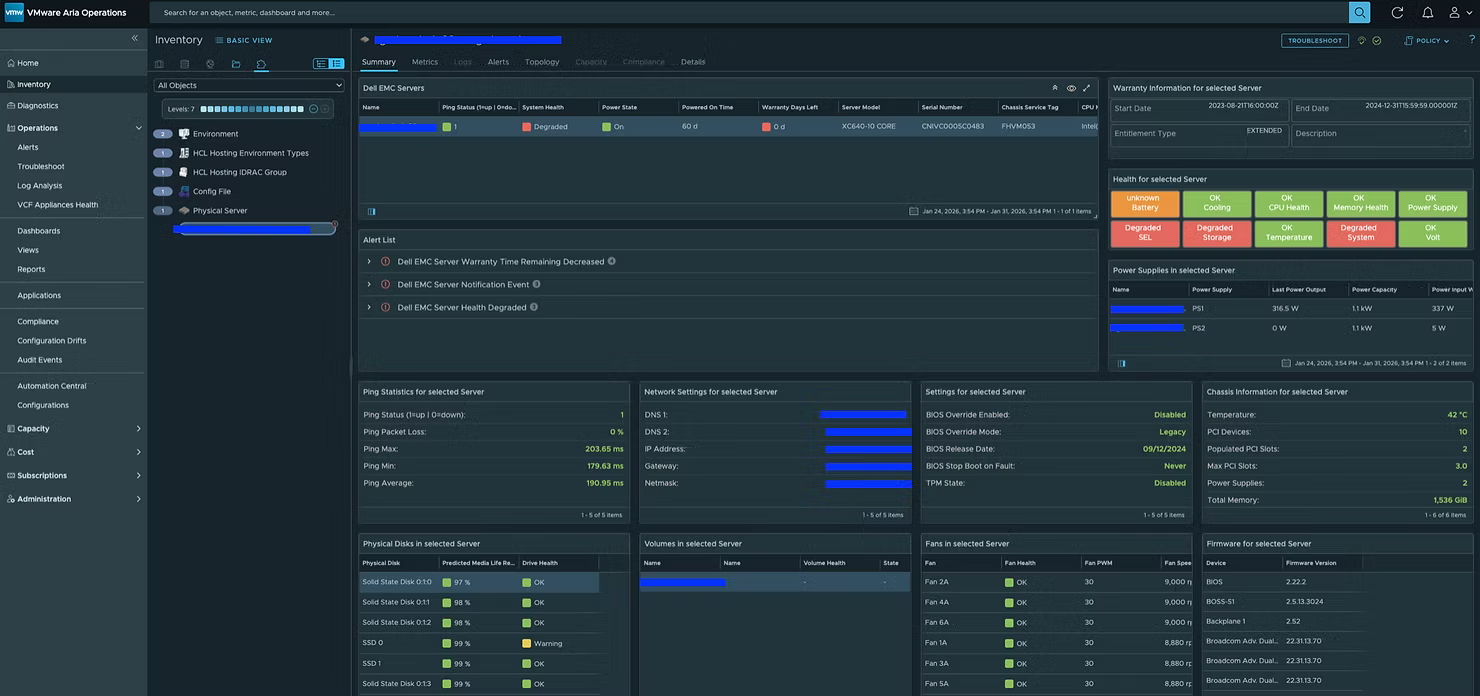
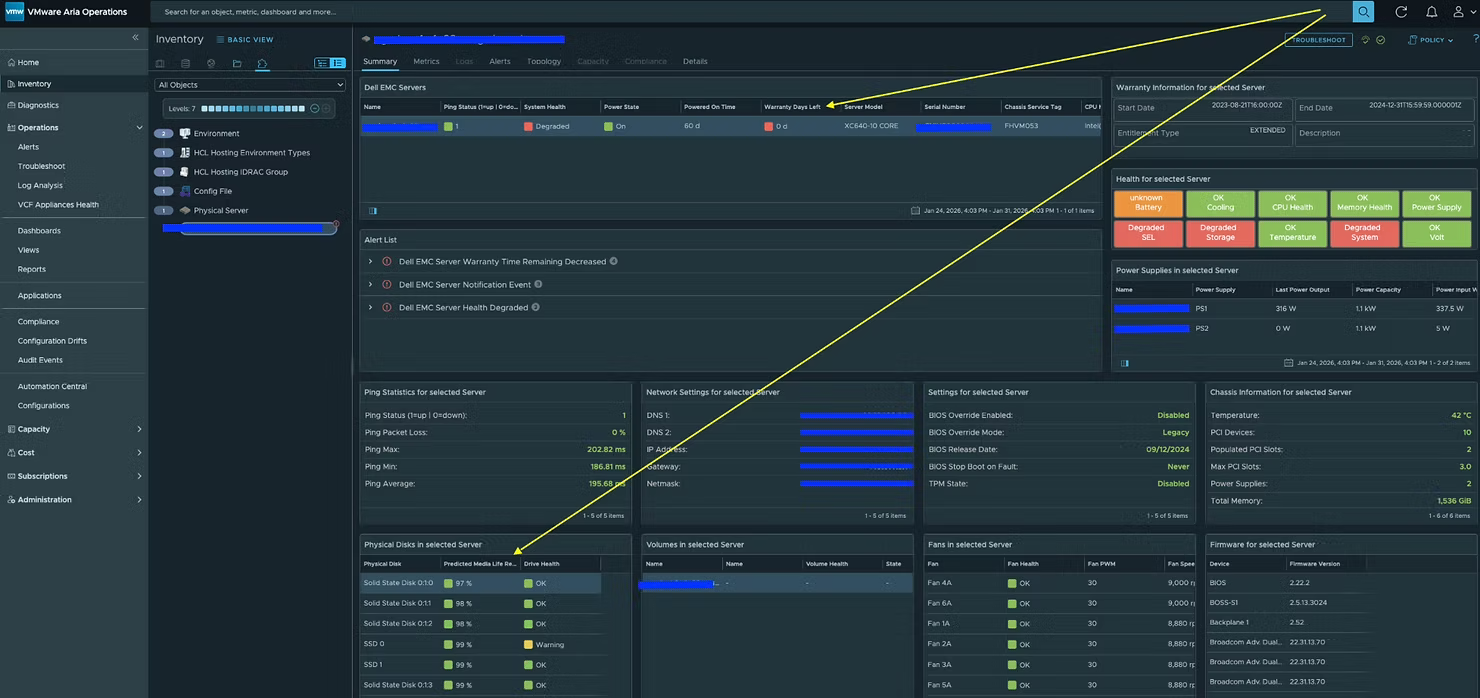
MP собирает десятки метрик и свойств не только по самому серверу, но также по батареям, блокам питания, вентиляторам и другим компонентам. Кроме того, был добавлен бонусный дашборд (Dell EMC Server Details), который при желании можно использовать в качестве страницы сводной информации по физическому серверу (Physical Server Summary Page).
Чтобы настроить этот дашборд как страницу сводки физического сервера, выполните описанные здесь действия. После настройки он будет выглядеть следующим образом.
vCommunity Hardware Management Pack также включает алерты, как показано ниже:
Два ключевых свойства, которые собираются и по которым формируются оповещения — это остаточный прогнозируемый срок службы физического диска (Physical Disk Predicted Media Life Remaining) и оставшийся срок гарантии (Warranty Remaining), что позволяет администраторам заблаговременно планировать обслуживание и предотвращать проблемы.
В дальнейшем планируется расширение функциональности, включая связи с хостами ESX и поддержку дополнительных аппаратных платформ. Скачивайте и начинайте использовать уже сегодня!
Это заключительная часть серии статей (см. прошлые части тут, тут, тут, тут, тут и тут), посвящённых технологии Memory Tiering. В предыдущих публикациях мы рассмотрели архитектуру, проектирование, расчёт ёмкости и базовую настройку, а также другие темы. Теперь мы переходим к расширенной конфигурации. Эти параметры не являются обязательными для работы функции как таковой, но предоставляют дополнительные возможности - такие как шифрование данных и настройка соотношений памяти, но и не только.
Хотя значения по умолчанию в vSphere в составе VMware Cloud Foundation 9.0 разработаны так, чтобы «просто работать» в большинстве сред, для настоящей оптимизации требуется тонкая настройка. Независимо от того, используете ли вы виртуальные рабочие столы или базы данных, важно понимать, какие рычаги управления стоит задействовать.
Ниже описано, как освоить расширенные параметры для настройки соотношений памяти, шифрования на уровне хоста и отдельных ВМ, а также отключения технологии Memory Tiering на уровне отдельных машин.
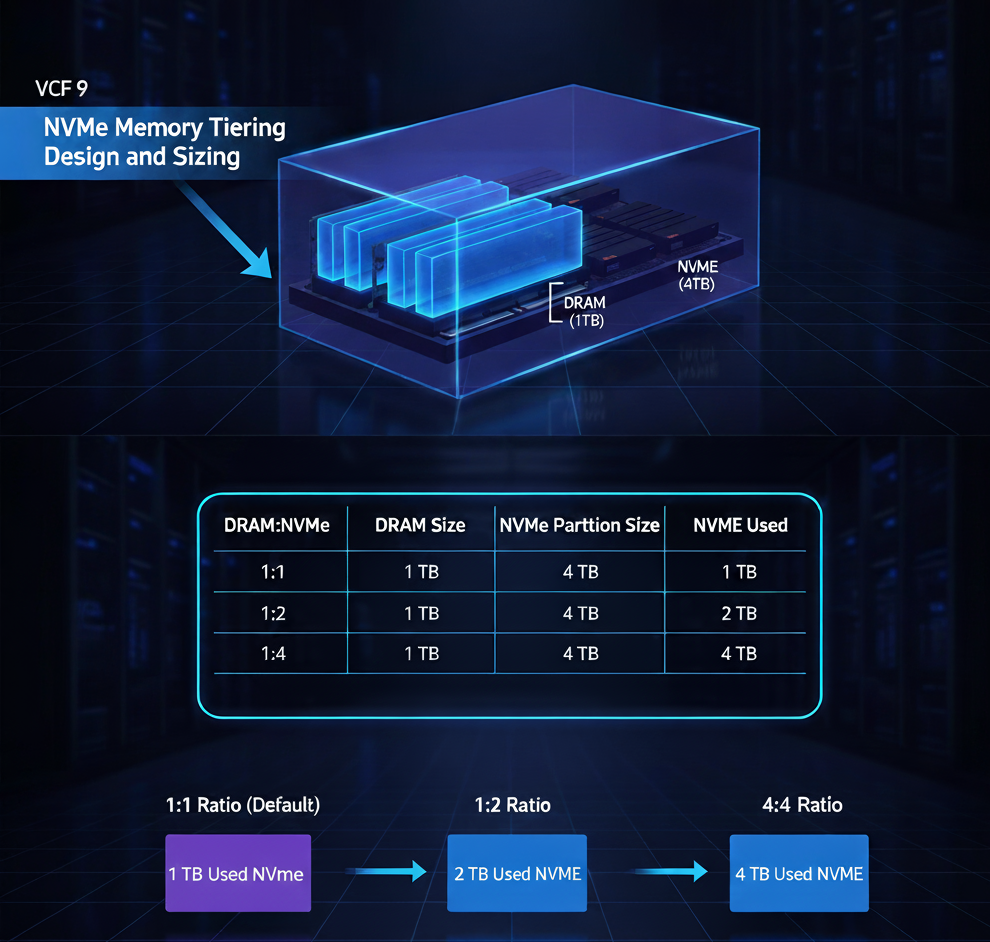
Настройка соотношения DRAM:NVMe
По умолчанию при включении Memory Tiering ESX устанавливает соотношение DRAM к NVMe равным 1:1, то есть 100% дополнительной памяти за счёт NVMe. Это означает, что при наличии 512 ГБ DRAM хост получит ещё 512 ГБ NVMe-ёмкости в качестве памяти Tier 1, что в сумме даст 1 ТБ памяти.
Однако в зависимости от типа рабочих нагрузок вы можете захотеть изменить эту плотность. Например, в VDI-среде, где ключевым фактором является стоимость одного рабочего стола, может быть выгодно использовать более высокое соотношение (больше NVMe на каждый гигабайт DRAM). Напротив, для кластеров с высокими требованиями к производительности вы можете захотеть ограничить размер NVMe-яруса.
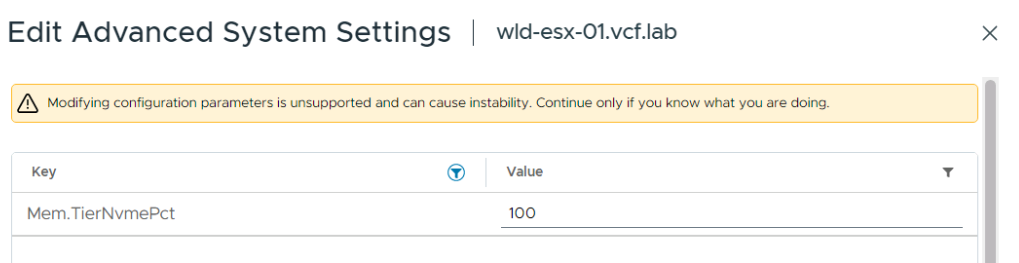
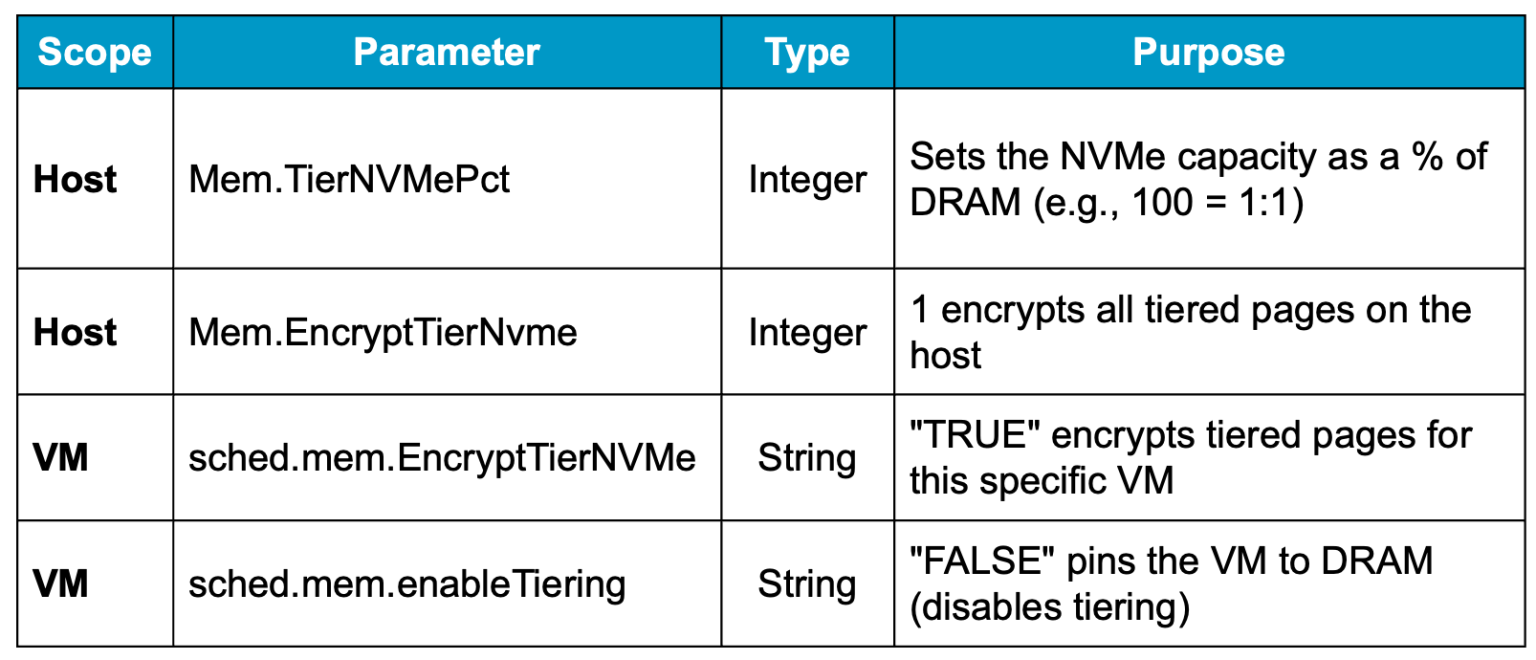
Управление этим параметром осуществляется через расширенную системную настройку хоста: Mem.TierNVMePct.
Параметр
Где настраивается: Host Advanced System Settings
Ключ: Mem.TierNVMePct
Значение: процент DRAM, используемый в качестве NVMe-яруса
Возможные значения:
100 (по умолчанию): 100% от объёма DRAM (соотношение 1:1)
200: 200% от объёма DRAM (соотношение 1:2)
50: 50% от объёма DRAM — очень консервативный вариант (соотношение 2:1)
Примечание. Рекомендации и лучшие практики предполагают сохранение соотношения по умолчанию 1:1, так как оно подходит для большинства рабочих нагрузок. Если вы решите изменить это соотношение, необходимо предварительно тщательно проанализировать свои нагрузки и убедиться, что вся активная память может быть размещена в объёме DRAM хоста. Подробнее о расчёте ёмкости Memory Tiering см. вот тут.
Защита уровня: шифрование
Одним из архитектурных различий между DRAM и NVMe является постоянство хранения данных. В то время как обычная оперативная память теряет данные (практически) мгновенно при отключении питания, NVMe является энергонезависимой. Несмотря на то что VMware выполняет очистку страниц памяти, организации с повышенными требованиями к безопасности (особенно в регулируемых отраслях) часто требуют шифрование данных «на диске» (Data-at-Rest Encryption) для любых данных, записываемых на накопители, даже если эти накопители используются как память. Более подробное описание шифрования NVMe в контексте Memory Tiering приведено вот тут.
Здесь доступны два уровня управления: защита всего NVMe-уровня хоста целиком либо выборочное шифрование данных только для определённых виртуальных машин, вместо шифрования данных всех ВМ на хосте.
Вариант A: шифрование на уровне хоста
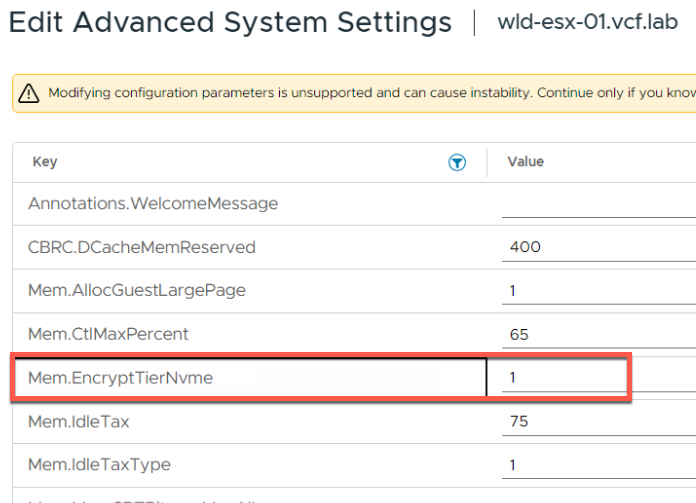
Это «универсальный» подход. Он гарантирует, что любая страница памяти, перемещаемая из DRAM в NVMe-уровень на данном хосте, будет зашифрована с использованием алгоритма AES-XTS.
Параметр
Где настраивается:Host Advanced Configuration Parameters
Ключ: Mem.EncryptTierNvme
Значение: 1 — включено, 0 — отключено
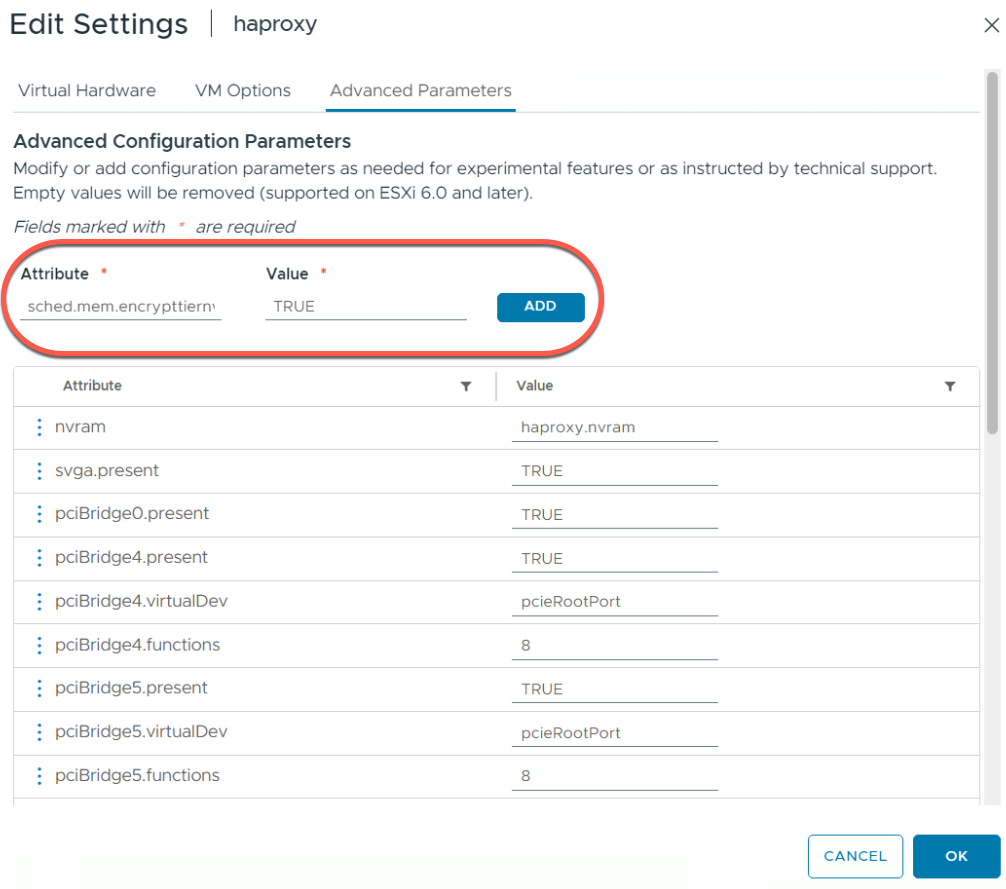
Вариант Б: шифрование на уровне виртуальной машины
Если вы хотите включить шифрование только для отдельных виртуальных машин — то есть шифровать лишь те страницы памяти, которые размещаются на NVMe, — вы можете применить эту настройку только к наиболее критичным рабочим нагрузкам (например, контроллерам домена или финансовым базам данных).
Параметр
Где настраивается: VM Advanced Configuration Parameters
Ключ: sched.mem.EncryptTierNVMe
Значение: TRUE
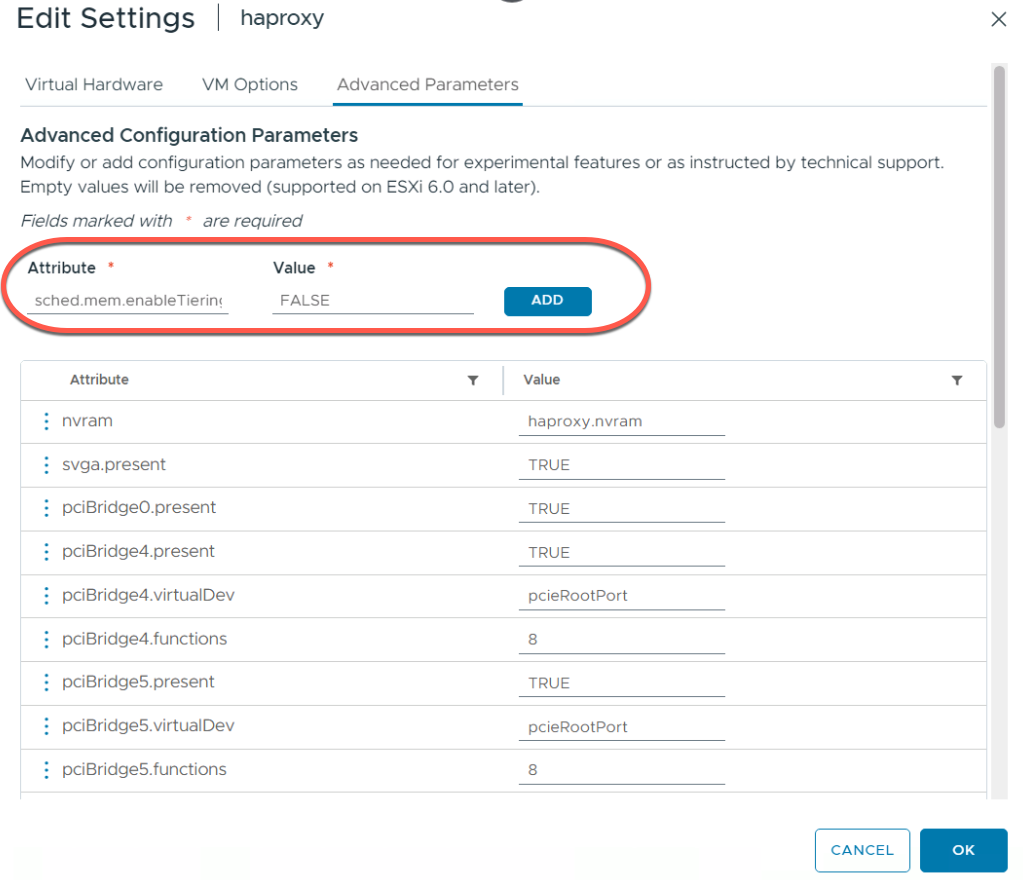
Отказ от использования: отключение Memory Tiering для критичных ВМ
Memory Tiering отлично подходит для «холодных» данных, однако «горячие» данные должны находиться в DRAM. Несмотря на то, что планировщик ESX чрезвычайно интеллектуален в вопросах размещения страниц памяти, некоторые рабочие нагрузки слишком чувствительны, чтобы допускать даже минимальные всплески задержек, связанные с использованием Memory Tiering.
Типичные сценарии использования:
SAP HANA и другие in-memory базы данных
Приложения для высокочастотной торговли (High-Frequency Trading)
Виртуальные машины безопасности
Кроме того, существуют профили виртуальных машин, которые в настоящее время не поддерживают Memory Tiering, такие как ВМ с низкой задержкой, ВМ с Fault Tolerance (FT), ВМ с большими страницами памяти (large memory pages) и др. Для таких профилей Memory Tiering необходимо отключать на уровне виртуальной машины. Это принудительно размещает страницы памяти ВМ исключительно в Tier 0 (DRAM). Полный список профилей ВМ см. в официальной документации VMware.
Параметр
Где настраивается: VM Advanced Configuration Parameters
Ключ: sched.mem.enableTiering
Значение: FALSE
Ну и в заключение - таблица расширенных параметров Memory Tiering:
Memory Tiering в VCF 9.0 представляет собой серьёзный сдвиг в подходе к плотности серверов и интеллектуальному потреблению ресурсов. Эта технология уводит нас от жёсткого «потолка по RAM» и предоставляет гибкий, экономически эффективный буфер памяти. Однако, как и в случае с любым мощным инструментом, значения по умолчанию — лишь отправная точка. Используя описанные выше параметры, вы можете настроить поведение системы в соответствии как с ограничениями бюджета, так и с требованиями SLA.
Наверняка не всем из вас знаком ресурс virten.net — технический портал, посвящённый информации, новостям, руководствам и инструментам для работы с продуктами VMware и виртуализацией. Сайт предлагает полезные ресурсы как для ИТ-специалистов, так и для энтузиастов виртуализации, включая обзоры версий, документацию, таблицы сравнений и практические руководства.
Там можно найти:
Новости и статьи о продуктах VMware (релизы, обновления, сравнения версий, технические обзоры).
Полезные разделы по VMware vSphere, ESX, vCenter и другим продуктам, включая истории релизов, конфигурационные лимиты и различия между версиями.
Практические инструменты и утилиты, такие как декодеры SCSI-кодов, RSS-трекер релизов (vTracker), помощь по OVF/PowerShell, события vCenter и JSON-репозиторий полезных данных.
Давайте посмотрим, что на этом сайте есть полезного для администраторов инфраструктуры VMware Cloud Foundation.
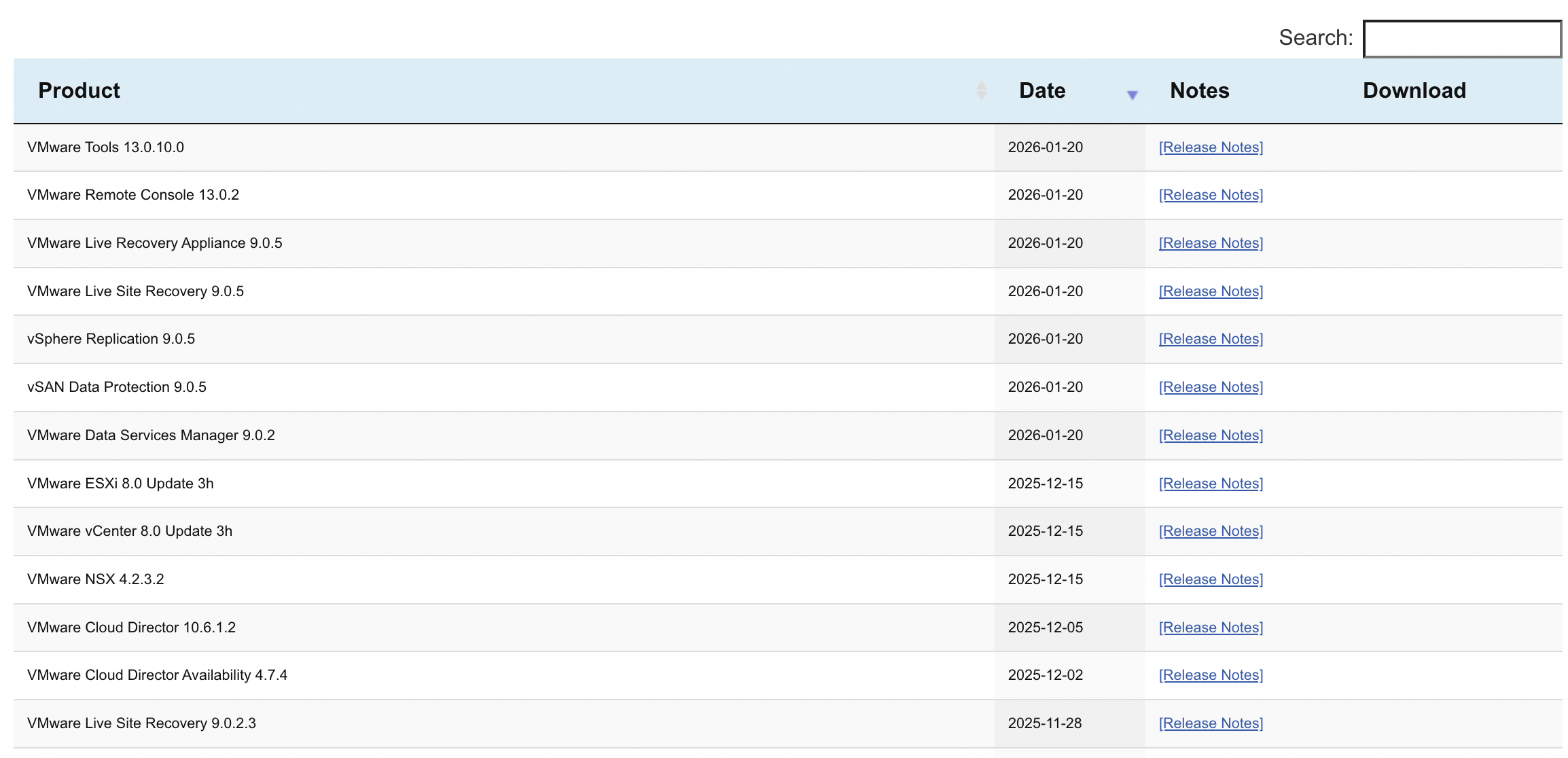
Эта страница содержит список продуктов, выпущенных компанией VMware. vTracker автоматически обновляется, когда на сайте vmware.com становятся доступны для загрузки новые продукты (GA — общедоступный релиз). Если вы хотите получать уведомления о выходе новых продуктов VMware, подпишитесь на RSS-ленту. Вы также можете использовать экспорт в формате JSON для создания собственного инструмента. Не стесняйтесь оставлять там комментарии, если у вас есть предложения по новым функциям.
Если вы просто хотите узнать, какая версия того или иного продукта VMware сейчас актуальна, самый простой способ - это посмотреть вот эту таблицу с функцией поиска:
В этом разделе представлен полный перечень релизов флагманского гипервизора VMware ESX (ранее ESXi). Все версии, выделенные жирным шрифтом, доступны для загрузки. Все патчи указаны под своими официальными названиями релизов, датой выхода и номером билда. Обратите внимание, что гипервизор ESXi доступен начиная с версии 3.5.
Если вы столкнулись с какими-либо проблемами при работе с этим сайтом или заметили отсутствие сборок, пожалуйста, свяжитесь с автором.
Эта страница представляет собой коллекцию заранее настроенных фрагментов PowerShell-скриптов для развертывания OVF/OVA. Идея заключается в ускорении процесса развертывания, если вам необходимо устанавливать несколько виртуальных модулей, выполнять повторное развертывание из-за неверных входных данных или сохранить файл в качестве справочного примера для будущих установок.
Просто заполните подготовленные переменные так же, как вы обычно делаете это в клиенте vSphere, и запустите скрипт. Все шаблоны используют одинаковую последовательность действий и тексты подсказок из мастера развертывания. Необязательные параметры конфигурации можно закомментировать. Если у параметров есть значения по умолчанию, они уже заполнены.
Ошибки или предупреждения SCSI в логах и интерфейсе ESX отображаются с использованием 6 кодов состояния. Эта страница преобразует эти коды, полученные от хостов ESX, в понятную для человека информацию о состоянии подсистемы хранения. В системном журнале vmkernel.log на хостах ESXi версии 5.x или 6.0 вы можете увидеть записи, подобные приведённым ниже. На странице декодера вы можете ввести нужные числа в форму и получить пояснения по сообщениям SCSI:
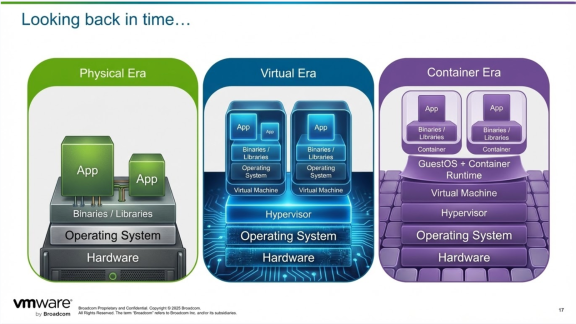
Виртуализация решила основную проблему «один сервер — одно приложение». Контейнеризация опиралась на этот результат и уточнила способ его достижения. Однако виртуализация остаётся основой современной вычислительной среды, и многие из наиболее критически важных рабочих нагрузок в мире продолжают и будут продолжать работать в виртуальных машинах. Помимо своей долговечности, виртуализация улучшает контейнеризацию и Kubernetes, помогая обеспечивать ключевые результаты, которых ожидают пользователи и которые требуются бизнесу.
Администраторы ИТ-инфраструктур и ИТ-менеджеры часто задают вопросы наподобие: «Какое отношение виртуализация имеет к Kubernetes?» Понимание этого крайне важно для ИТ-подразделений и организационных бюджетов. Вычисления революционизировали то, как мы взаимодействуем друг с другом, как работаем, и сформировали рамки возможного в промышленности. ИТ-нагрузки требуют вычислительных ресурсов, таких как CPU, память, хранилище, сеть и т. д., чтобы выполнять нужные функции — например, отправку электронного письма или обновление базы данных. Важная часть бизнес-операций заключается в том, чтобы ИТ-организации оптимизировали стратегию размещения своих нагрузок — будь то на мейнфрейме, в локальном дата-центре или в публичном облаке.
Виртуализация не исчезла с появлением Kubernetes — напротив, она помогает Kubernetes работать лучше в масштабе предприятия.
Виртуализация
С зарождения электронной вычислительной техники в 1940-х годах пользователи взаимодействовали с выделенным физическим оборудованием для выполнения своих задач. Приложения, рабочие нагрузки и оборудование стремительно развивались и расширяли возможности, сложность и охват того, что пользователи могли делать с помощью вычислений. Однако оставалось ключевое ограничение — одна машина, или сервер, выделялась под одно приложение. Например, у организаций были серверы, выделенные под почтовую функциональность, или целый сервер, выделенный под действия, выполнявшиеся лишь несколько раз в месяц, такие как начисление заработной платы.
Виртуализация — использование технологий для имитации ИТ-ресурсов — была впервые реализована в 1960-х годах на мейнфреймах. В ту эпоху виртуализация обеспечивала совместный доступ к ресурсам мейнфрейма и позволяла использовать мейнфреймы для нескольких приложений и сценариев. Это стало прообразом современной виртуализации и облачных вычислений, позволяя нескольким приложениям работать на выделенном оборудовании.
VMware возглавила бум облачных вычислений благодаря виртуализации архитектуры x86 — самого распространённого набора инструкций для персональных компьютеров и серверов. Теперь физическое оборудование могло размещать несколько распределённых приложений, поддерживать многих пользователей и полностью использовать дорогостоящее «железо». Виртуализация — ключевая технология, которая делает возможными публичные облачные вычисления; ниже приведено резюме:
Абстракция: виртуализация абстрагирует физическое оборудование, предоставляющее CPU, RAM и хранилище, в логические разделы, которыми можно управлять независимо.
Гибкость, масштабируемость, эластичность: абстрагированные разделы теперь можно масштабировать под потребности бизнеса, выделять и отключать по требованию, а ресурсы - возвращать по мере необходимости.
Консолидация ресурсов и эффективность: физическое оборудование теперь может запускать несколько логических разделов «правильного размера» с нужным объёмом CPU, RAM и хранилища — максимально используя оборудование и снижая постоянные затраты, такие как недвижимость и электроэнергия.
Изоляция и безопасность: у каждой ВМ есть собственный «мир» с ОС, независимой от той, что запущена на физическом оборудовании, что обеспечивает глубокую безопасность и изоляцию для приложений, использующих общий хост.
Для большинства предприятий и организаций критически важные рабочие нагрузки, обеспечивающие их миссию, рассчитаны на работу в виртуальных машинах, и они доверяют Broadcom предоставлять лучшие ВМ и лучшие технологии виртуализации. Доказав, что инфраструктуру можно абстрагировать и управлять ею независимо от физического оборудования, виртуализация заложила основу для следующей эволюции размещения рабочих нагрузок.
Контейнеризация
По мере роста вычислительных потребностей экспоненциально росла и сложность приложений и рабочих нагрузок. Приложения, которые традиционно проектировались и управлялись как монолиты, то есть как единый блок, начали разбиваться на меньшие функциональные единицы, называемые микросервисами. Это позволило разработчикам и администраторам приложений управлять компонентами независимо, упрощая масштабирование, обновления и повышая надёжность. Эти микросервисы запускаются в контейнерах, которые стали популярны в отрасли благодаря Docker.
Контейнеры Docker упаковывают приложения и их зависимости - такие как код, библиотеки и конфигурационные файлы - в единицы, которые могут стабильно работать на любой инфраструктуре: будь то ноутбук разработчика, сервер в датацентре предприятия или сервер в публичном облаке. Контейнеры получили своё название по аналогии с грузовыми контейнерами и дают многие из тех же преимуществ, что и их физические «тёзки», такие как стандартизация, переносимость и инкапсуляция. Ниже — краткий обзор ключевых преимуществ контейнеризации:
Стандартизация: как грузовые контейнеры упаковывают товары в формат, с которым другое оборудование может взаимодействовать единообразно, так и программные контейнеры упаковывают приложения в унифицированную, логически абстрагированную и изолированную среду
Переносимость: грузовые контейнеры перемещаются с кораблей на грузовики и поезда. Программные контейнеры могут запускаться на ноутбуке разработчика, в средах разработки, на продакшн-серверах и между облачными провайдерами
Инкапсуляция: грузовые контейнеры содержат всё необходимое для выполнения заказа. Программные контейнеры содержат код приложения, среду выполнения, системные инструменты, библиотеки и любые другие зависимости, необходимые для запуска приложения.
Изоляция: и грузовые, и программные контейнеры изолируют своё содержимое от других контейнеров. Программные контейнеры используют общую ОС физической машины, но не зависимости приложений.
По мере того как контейнеры стали отраслевым стандартом, команды начали разрабатывать собственные инструменты для оркестрации и управления контейнерами в масштабе. Kubernetes появился из этих проектов в 2015 году, а затем был передан сообществу open source. Продолжая морскую тематику контейнеров, Kubernetes по-гречески означает «рулевой» или «пилот» и выполняет роль мозга инфраструктуры.
Контейнер позволяет легко развёртывать приложения - Kubernetes позволяет масштабировать число экземпляров приложения, он гарантирует, что каждый экземпляр остаётся запущенным, и работает одинаково у любого облачного провайдера или в любом датцентре. Это три «S»-столпа: самовосстановление (Self-Healing), масштабируемость (Scalability) и стандартизация (Standardization). Эти результаты ускорили рост Kubernetes до уровня отраслевого золотого стандарта, и он стал повсеместным в cloud native-вычислениях, обеспечивая операционную согласованность, снижение рисков и повышенную переносимость.
Виртуализация > Контейнеризация
Виртуализация проложила путь разработчикам к размещению и изоляции нескольких приложений на физическом оборудовании, администраторам — к управлению ИТ-ресурсами, отделёнными от базового оборудования, и доказала жизнеспособность абстрагирования нижних частей стека для запуска и масштабирования сложного ПО. Контейнеры развивают эти принципы и абстрагируют уровень приложений, предоставляя следующие преимущества по сравнению с виртуализацией:
Эффективность: благодаря общей ОС контейнеры устраняют накладные расходы (CPU, память, хранилище), связанные с запуском нескольких одинаковых ОС для приложений.
Скорость: меньший «вес» позволяет значительно быстрее запускать и останавливать.
Переносимость: контейнеры лёгкие и могут выполняться на любом совместимом контейнерном рантайме.
Виртуализация улучшает Kubernetes
Виртуализация также стабилизирует и ускоряет Kubernetes. Большинство управляемых Kubernetes-сервисов, включая предложения гиперскейлеров (EKS на AWS, AKS на Azure, GKE на GCP), запускают Kubernetes-слой поверх виртуализованной ОС. Поскольку Kubernetes-среды обычно сложны, виртуализация значительно усиливает изоляцию, безопасность и надёжность, а также упрощает операции управления накладными процессами. Краткий обзор преимуществ:
Изоляция и безопасность: без виртуализации все контейнеры, работающие в кластере Kubernetes на физическом хосте, используют один и тот же Kernel (ядро ОС). Если контейнер взломан, всё, что работает на физическом хосте, потенциально может быть скомпрометировано на уровне оборудования. Гипервизор препятствует распространению злоумышленников на другие узлы Kubernetes и контейнеры.
Надёжность: Kubernetes может перезапускать контейнеры, если те падают, но бессилен, если проблемы возникают на уровне физического хоста. Виртуализация может перезапустить окружение Kubernetes за счёт высокой доступности (High Availability) на другом физическом сервере.
Операции: без виртуализации весь физический хост обычно принадлежит одному Kubernetes-кластеру. Это означает, что среда привязана к одной версии Kubernetes, что снижает скорость развития и делает апгрейды и операции сложными.
Именно поэтому каждый крупный управляемый Kubernetes-сервис работает на виртуальных машинах: виртуализация обеспечивает изоляцию, надёжность и операционную гибкость, необходимые в корпоративном масштабе.
Broadcom предоставляет лучшую платформу для размещения рабочих нагрузок
Инженерные команды Broadcom продолжают активно участвовать в upstream Kubernetes и вносят вклад в такие проекты, как Harbor, Cluster API и etcd.
С выпуском VCF 9 подразделение VCF компании Broadcom принесло в отрасль унифицированные операции, общую инфраструктуру и единые инструменты, независимые от форм-факторов рабочих нагрузок. Клиенты могут запускать ВМ и контейнеры/Kubernetes-нагрузки на одном и том же оборудовании и управлять ими одними и теми же инструментами, на которых миллионы специалистов построили свои навыки и карьеры. Предприятия и организации могут снизить капитальные и операционные расходы, стандартизировать операционную модель и модернизировать приложения и инфраструктуру, чтобы бизнес мог двигаться быстрее, защищать данные и повышать надёжность своих ключевых систем.
В этой части статей о технологии NVMe Memory Tiering (см. прошлые части тут, тут, тут, тут и тут) мы поговорим о настройке этой технологии на серверах VMware ESX инфраструктуры VCF.
На протяжении всей этой серии статей мы рассматривали важные аспекты, которые следует учитывать перед настройкой Memory Tiering, такие как проектирование, подбор размеров, совместимость, избыточность, безопасность и многое другое. Теперь пришло время применить то, чему вы научились, и оптимизировать эту функцию для вашей среды, бюджета и стратегии.
Поскольку во многих статьях подробно описаны шаги настройки, этот пост будет сосредоточен на подходе высокого уровня и будет ссылаться на предыдущие посты для конкретных разделов. Всегда полагайтесь на официальную документацию Broadcom для точных шагов настройки — официальное руководство можно найти здесь, ну а основные аспекты развертывания Memory Tiering мы описывали тут.
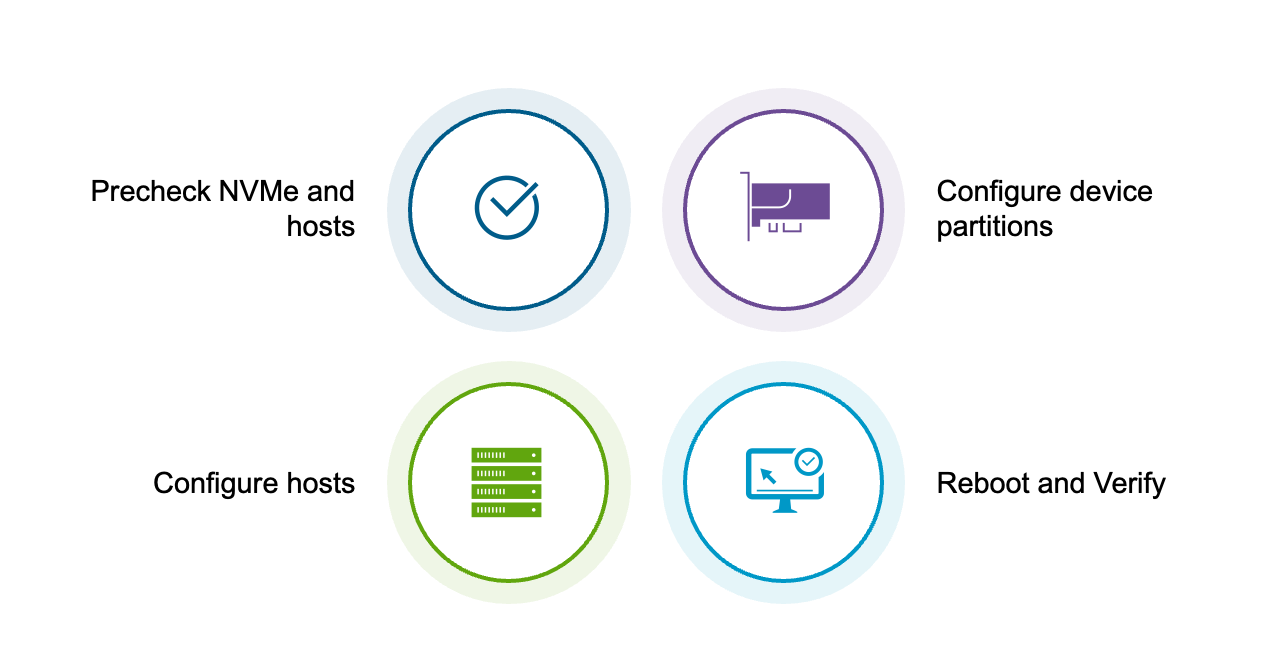
Шаги настройки
Технически для настройки Memory Tiering в вашей среде требуется всего два шага, но мы добавили задачи до и после настройки, чтобы обеспечить должную тщательность и проверить внедрение.
Предварительные проверки
Плотники живут по правилу «семь раз отмерь — один раз отрежь», потому что после разреза нельзя прокрутить фарш обратно. Чтобы избежать критических ошибок при настройке, мы должны сначала убедиться, что приняли правильные архитектурные решения для нашей среды.
После того как вы приняли все эти важные решения, этап предварительных проверок включает подтверждение того, что устройства корректно отображаются на всех ESX-хостах. Вам понадобится UID каждого устройства, чтобы создать раздел, который будет использоваться Memory Tiering.
Создание разделов
Первый шаг — создание раздела для каждого NVMe-устройства. Независимо от того, разворачиваете ли вы одно устройство на хост или используете аппаратный RAID, раздел требуется на каждом логическом NVMe-устройстве.
Методы:
ESXCLI: выполните стандартную команду esxcli (подробности тут).
PowerShell: создайте скрипт для автоматизации процесса. Пример скрипта доступен тут, он может быть изменён под среду вашего кластера.
Частые вопросы
Вопрос: Могу ли я настроить разделы на двух устройствах без RAID на одном и том же хосте для обеспечения избыточности?
Ответ: Нет. Хотя VCF 9.0 позволяет без ошибок создавать разделы Memory Tiering на нескольких устройствах на хост, система не объединяет их и не зеркалирует данные.
Результат: Memory Tiering смонтирует только один диск, выбранный недетерминированным образом в процессе загрузки. Второй диск будет проигнорирован и не даст ни избыточности, ни увеличения ёмкости (см. будущую информацию об обновлении VCF 9.1 - там что-то может поменяться).
Включение Memory Tiering
Этот шаг активирует функцию Memory Tiering. Вы можете выполнить эту настройку через ESXCLI, PowerShell или интерфейс vCenter UI, применяя её к отдельным хостам или ко всему кластеру одновременно.
Вопрос: Требуется ли настраивать Memory Tiering на всех хостах в кластере VCF 9.0?
Ответ: Нет. У вас есть возможность выбрать конкретные хосты для Memory Tiering.
Хотя идеально, чтобы все хосты имели одинаковую конфигурацию, все понимают, что определённые ограничения ВМ могут потребовать исключений (см. тут).
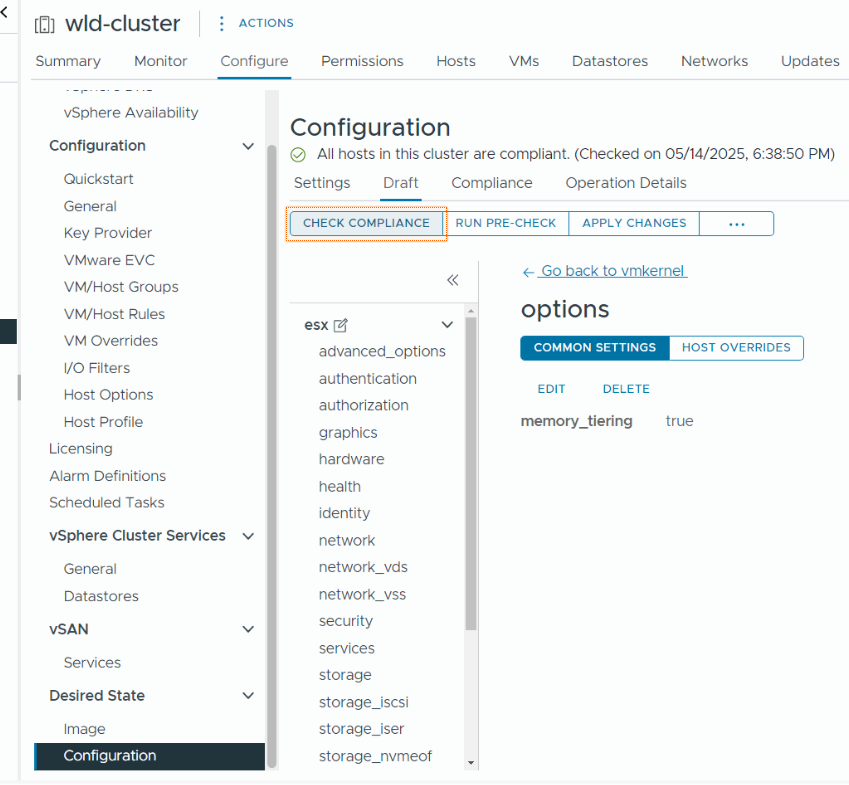
Самый эффективный способ настроить Memory Tiering — использовать профили конфигурации vSphere. Это позволяет включить функцию сразу на всех ваших хостах, одновременно используя переопределения хостов для тех хостов, где вы не хотите включать её. Подробнее — тут.
Финальный шаг
Последний шаг прост: перезагрузите все хосты и выполните проверку. В VCF/VVF 9.0 перезагрузка является обязательной, чтобы эта функция вступила в силу.
Если вы используете профили конфигурации (Configuration Profiles), система автоматизирует поочерёдные перезагрузки (одна за другой), одновременно мигрируя ВМ, чтобы они оставались в сети. И если вам интересно, обеспечивает ли этот метод также доступность данных vSAN - ответ: да.
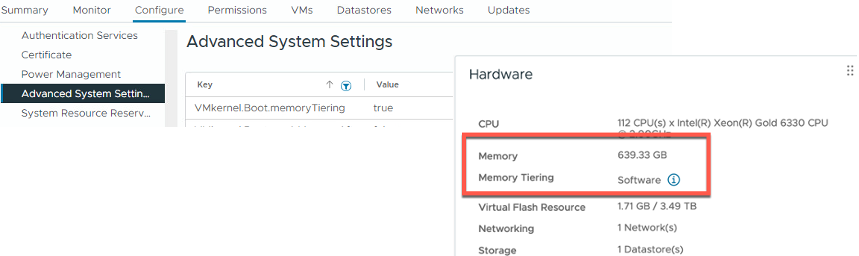
После того как все хосты снова будут онлайн, вы увидите новые элементы в интерфейсе, расположенные в разделах Advanced System Settings, на вкладке Monitor, а также Configure > Hardware > Overview > Memory.
Вы также должны увидеть, что по умолчанию объём доступной памяти увеличился в 2 раза как на уровне хоста, так и на уровне кластера. Вот это простой и недорогой способ удвоить ваш объём памяти!
В заключение: включение Memory Tiering - очень простой и понятный процесс. В качестве бонуса добавляем ссылку на актуальную лабораторную работу (Hands-on Lab), посвящённую Memory Tiering. Там вы можете выполнить настройку «от начала до конца», включая расширенные параметры, которые будут рассмотрены в следующих постах.
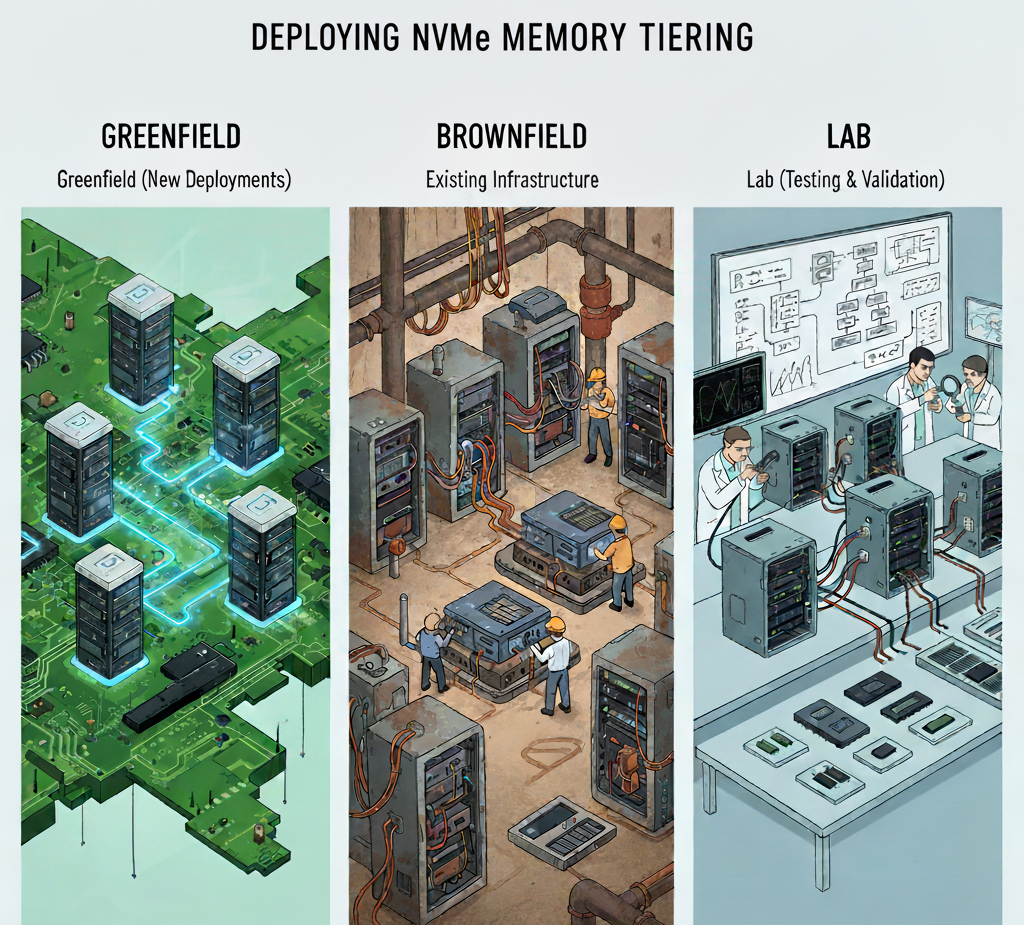
В этой части статей о технологии NVMe Memory Tiering (см. прошлые части тут, тут, тут и тут) мы предоставим некоторую информацию о различиях при включении Memory Tiering в разных сценариях. Хотя основной процесс остаётся тем же, есть моменты, которые могут потребовать дополнительного внимания и планирования, чтобы сэкономить время и усилия. Когда мы говорим о сценариях greenfield, мы имеем в виду совершенно новые развертывания VMware Cloud Foundation (VCF), включая новое оборудование и новую конфигурацию для всего стека. Сценарии brownfield будут охватывать настройку Memory Tiering в существующей среде VCF. Наконец, мы рассмотрим и лабораторные сценарии, поскольку встречаются неоднозначные утверждения о том, что это не поддерживается, но мы рассмотрим это в конце данной статьи.
Greenfield-развертывания
Давайте начнём с процесса конфигурации сред greenfield. Ранее мы рассказали о том, как VMware vSAN и Memory Tiering совместимы и могут сосуществовать в одном и том же кластере. Мы также обращали внимание на кое-что важное, о чём вам следует помнить во время greenfield-развертываний VCF. Начиная с VCF 9.0, включение Memory Tiering — это операция «Day 2», то есть сначала вы настраиваете VCF, а затем можете настроить Memory Tiering, но в ходе рабочего процесса развертывания VCF вы заметите, что опции для включения Memory Tiering (пока) нет, зато можно включить vSAN. То, как вы поступите с вашим NVMe-устройством, выделенным для Memory Tiering, будет определять шаги, необходимые для того, чтобы это устройство было представлено для его конфигурации.
Если все NVMe-устройства и для vSAN, и для Memory Tiering присутствуют во время развертывания VCF, есть вероятность, что vSAN может автоматически занять все накопители (включая NVMe-устройство, которое вы выделили для Memory Tiering). В этом случае вам пришлось бы удалить накопитель из vSAN после конфигурации, стереть разделы, а затем начать настройку Memory Tiering. Этот шаг был рассмотрен тут.
Другой подход — извлечь или не устанавливать устройство Memory Tiering в сервер и добавить его обратно в сервер после развертывания VCF. Таким образом вы не будете рисковать тем, что vSAN автоматически займет NVMe для Memory Tiering. Хотя это и не является серьёзным препятствием, всё равно полезно знать, что произойдёт и почему, чтобы вы могли быстро выделить ресурсы, необходимые для настройки Memory Tiering.
Brownfield-развертывания
Сценарии brownfield немного проще, так как VVF/VCF уже настроен; однако vSAN мог быть включён или ещё нет.
Если vSAN не включён, вам нужно будет отключить функцию auto-claim, пройти через конфигурацию vSAN и вручную выбрать ваши устройства (кроме NVMe-устройств для Memory Tiering). Всё выполняется в интерфейсе UI и по процедуре, которая используется уже много лет. Это гарантирует, что NVMe-устройство Memory Tiering будет доступно для настройки. Подробный процесс задокументирован в TechDocs.
Если vSAN уже включён, мы предполагаем, что NVMe-устройство для Memory Tiering только что было приобретено и готово к установке. Значит, всё, что нам нужно сделать, — добавить его в хост и убедиться, что оно корректно отображается как NVMe-устройство и что на нём нет существующих разделов. Это, вероятно, самый простой сценарий и самый распространённый.
Развертывания в тестовой среде
Теперь давайте поговорим о давно ожидаемом лабораторном сценарии. Для лаборатории типа bare metal, где сервер ESX одноуровневый и нет вложенных сред, применяются те же принципы greenfield и brownfield. Что касается вложенной (nested) виртуализации, многие говорят о том, что вложенный Memory Tiering не поддерживается. Ну, это и так, и не так.
Когда мы говорим о вложенных средах, мы имеем в виду два уровня ESX. Внешний уровень — это ESX, установленный на оборудовании (обычная настройка), а внутренний уровень ESX состоит из виртуальных машин, запускающих ESX и выступающих в роли как бы физических хостов. Memory Tiering МОЖЕТ быть включён на внутреннем уровне (вложенном), и все параметры конфигурации работают нормально. Мы делаем следующее: берём datastore и создаём виртуальный Hard Disk типа NVMe, чтобы представить его виртуальной машине, которая выступает в роли вложенного хоста. Хотя мы видим NVMe-устройство на вложенном хосте и можем настроить Memory Tiering, базовое устройство хранения состоит из устройств, формирующих выбранный datastore. Вы можете настроить Memory Tiering, и вложенные хосты смогут видеть hot и active pages, но не ожидайте какого-либо уровня производительности, учитывая, что компоненты базового хранилища построены на традиционных накопителях. Работает ли это? ДА, но только в лабораторных средах.
Тестирование в лабораторной среде очень полезно: оно помогает вам пройти шаги конфигурации и понять, как работает настройка и какие расширенные параметры можно задать. Это отличный вариант использования для подготовки (практики) к развертыванию в производственной среде или даже просто для знакомства с функцией, например, для целей сдачи сертификационного экзамена.
А как насчёт внешнего уровня? Ну, это как раз то, что не поддерживается в VCF 9.0, поскольку внешний уровень ESX не имеет видимости внутреннего уровня и не может видеть активность памяти ВМ, по сути пытаясь «прозреть» сквозь вложенный уровень до виртуальной машины (inception). Это и есть главное отличие (не вдаваясь слишком глубоко в технические детали).
Так что если вам интересно протестировать Memory Tiering, а всё, что у вас есть — это вложенная среда, вы можете настроить Memory Tiering и любые расширенные параметры. Интересно наблюдать, как несколько шагов настройки могут добавить хостам 100% дополнительной памяти.
В ранних статьях мы упоминали, что вы можете настраивать разделы NVMe с помощью команд ESXCLI, PowerCLI и даже скриптов. В более поздних публикациях мы говорили о том, что опубликуем скрипт для настройки разделов, который мы приводим ниже, но с оговоркой и прямым предупреждением: вы можете запускать скрипт на свой страх и риск, и он может не работать в вашей среде в зависимости от вашей конфигурации.
Рассматривайте этот скрипт только как пример того, как это можно автоматизировать, а не как поддерживаемое решение автоматизации. Кроме того, скрипт не стирает разделы за вас, поэтому убедитесь, что вы сделали это до запуска скрипта. Как всегда, сначала протестируйте.
Есть некоторые переменные, которые вам нужно изменить, чтобы он работал в вашей среде:
$vCenter = “ваш vCenter FQDN или IP” (строка 27)
$clusterName = “имя вашего кластера” (строка 28)
Вот и сам скрипт:
function Update-NvmeMemoryTier {
param (
[Parameter(Mandatory=$true)]
[VMware.VimAutomation.ViCore.Impl.V1.Inventory.VMHostImpl]$VMHost,
[Parameter(Mandatory=$true)]
[string]$DiskPath
)
try {
# Verify ESXCLI connection
$esxcli = Get-EsxCli -VMHost $VMHost -V2
# Note: Verify the correct ESXCLI command for NVMe memory tiering; this is a placeholder
# Replace with the actual command or API if available
$esxcli.system.tierdevice.create.Invoke(@{ nvmedevice = $DiskPath }) # Hypothetical command
Write-Output "NVMe Memory Tier created successfully on host $($VMHost.Name) with disk $DiskPath"
return $true
}
catch {
Write-Warning "Failed to create NVMe Memory Tier on host $($VMHost.Name) with disk $DiskPath. Error: $_"
return $false
}
}
# Securely prompt for credentials
$credential = Get-Credential -Message "Enter vCenter credentials"
$vCenter = "vcenter FQDN"
$clusterName = "cluster name"
try {
# Connect to vCenter
Connect-VIServer -Server $vCenter -Credential $credential -WarningAction SilentlyContinue
Write-Output "Connected to vCenter Server successfully."
# Get cluster and hosts
$cluster = Get-Cluster -Name $clusterName -ErrorAction Stop
$vmHosts = Get-VMHost -Location $cluster -ErrorAction Stop
foreach ($vmHost in $vmHosts) {
Write-Output "Fetching disks for host: $($vmHost.Name)"
$disks = @($vmHost | Get-ScsiLun -LunType disk |
Where-Object { $_.Model -like "*NVMe*" } | # Filter for NVMe disks
Select-Object CanonicalName, Vendor, Model, MultipathPolicy,
@{N='CapacityGB';E={[math]::Round($_.CapacityMB/1024,2)}} |
Sort-Object CanonicalName) # Explicit sorting
if (-not $disks) {
Write-Warning "No NVMe disks found on host $($vmHost.Name)"
continue
}
# Build disk selection table
$diskWithIndex = @()
$ctr = 1
foreach ($disk in $disks) {
$diskWithIndex += [PSCustomObject]@{
Index = $ctr
CanonicalName = $disk.CanonicalName
Vendor = $disk.Vendor
Model = $disk.Model
MultipathPolicy = $disk.MultipathPolicy
CapacityGB = $disk.CapacityGB
}
$ctr++
}
# Display disk selection table
$diskWithIndex | Format-Table -AutoSize | Out-String | Write-Output
# Get user input with validation
$maxRetries = 3
$retryCount = 0
do {
$diskChoice = Read-Host -Prompt "Select disk for NVMe Memory Tier (1 to $($disks.Count))"
if ($diskChoice -match '^\d+$' -and $diskChoice -ge 1 -and $diskChoice -le $disks.Count) {
break
}
Write-Warning "Invalid input. Enter a number between 1 and $($disks.Count)."
$retryCount++
} while ($retryCount -lt $maxRetries)
if ($retryCount -ge $maxRetries) {
Write-Warning "Maximum retries exceeded. Skipping host $($vmHost.Name)."
continue
}
# Get selected disk
$selectedDisk = $disks[$diskChoice - 1]
$devicePath = "/vmfs/devices/disks/$($selectedDisk.CanonicalName)"
# Confirm action
Write-Output "Selected disk: $($selectedDisk.CanonicalName) on host $($vmHost.Name)"
$confirm = Read-Host -Prompt "Confirm NVMe Memory Tier configuration? This may erase data (Y/N)"
if ($confirm -ne 'Y') {
Write-Output "Configuration cancelled for host $($vmHost.Name)."
continue
}
# Configure NVMe Memory Tier
$result = Update-NvmeMemoryTier -VMHost $vmHost -DiskPath $devicePath
if ($result) {
Write-Output "Successfully configured NVMe Memory Tier on host $($vmHost.Name)."
} else {
Write-Warning "Failed to configure NVMe Memory Tier on host $($vmHost.Name)."
}
}
}
catch {
Write-Warning "An error occurred: $_"
}
finally {
# Disconnect from vCenter
Disconnect-VIServer -Server $vCenter -Confirm:$false -ErrorAction SilentlyContinue
Write-Output "Disconnected from vCenter Server."
}
Переход на VMware Cloud Foundation (VCF) 9 — это не просто обновление версии платформы. Он включает ребрендинг ключевых сервисов, перенос функций между компонентами, а также существенные улучшения управления жизненным циклом (Lifecycle Management). Для команд, планирующих миграцию с VCF 5.x, важно понимать, что именно изменилось: какие элементы остались прежними, какие переименованы, а какие были полностью заменены.
Об этом в общих чертах мы писали в прошлой статье, а сегодня разберём переход с VCF 5.x серии на версию VCF 9 через призму:
Сравнения ключевых компонентов
Архитектурных изменений
Обновлений управления жизненным циклом
Замены компонентов и блоков функционала
Обо всем этом рассказывается в видео ниже:
Базовая архитектура управления: что осталось неизменным
SDDC Manager — ядро VCF остаётся тем же
Один из наиболее важных выводов: SDDC Manager по-прежнему остаётся центральным движком управления VCF, и он:
Присутствует как в VCF 5, так и в VCF 9
Не меняет название (нет ребрендинга)
Остаётся основным интерфейсом управления инфраструктурой
Однако отмечается, что в VCF 9 функциональность SDDC Manager расширена и улучшена по сравнению с 5-й серией.
Это важно, потому что SDDC Manager — "точка сборки" всей архитектуры VCF: он стабильный и развивается, миграции проще планировать и стандартизировать.
Изменения бренда и унификация: Aria -> VCF Operations
Одно из наиболее заметных изменений VCF 9 — это масштабный ребрендинг линейки VMware Aria в сторону единого зонтичного бренда VCF Operations.
VMware Aria Operations -> VCF Operations
Ранее компонент VMware Aria Operations выполнял роль:
Централизованных дашбордов
Мониторинга инфраструктуры
Уведомлений и alerting
SNMP-настроек
Кастомной отчётности (например, oversizing виртуальных машин)
Capacity planning
В VCF 9 этот же компонент переименован как часть стратегии VMware по движению к унифицированной "operations-платформе" в рамках VCF. Функционально компонент выполняет те же задачи, но позиционирование стало единым для всей платформы.
Operations-экосистема: логирование и сетевые инсайты
Aria Operations for Logs -> VCF Operations for Logs
Компонент логирования в VCF 5 назывался по-разному в средах заказчиков: Aria Operations for Logs и Log Insight. По сути — это централизованный syslog-агрегатор и анализатор, собирающий логи от всех компонентов VCF. В VCF 9 Aria Operations for Logs переименован VCF Operations for Logs. Функционально это тот же концепт, сбор логов остаётся централизованным и управляется как часть единого "Operations-стека".
Aria Operations for Network Insights -> VCF Operations for Network
Сетевой компонент прошёл длинный путь переименований: vRealize Network Insight, затем Aria Operations for Networks и, наконец, в VCF 9 он называется VCF Operations for Network.
Он обеспечивает:
Централизованный мониторинг сети
Диагностику
Анализ сетевого трафика
Возможности packet capture от источника до назначения
В VCF 5 жизненным циклом (апдейты/апгрейды) занимался компонент Aria Lifecycle Management (LCM), В VCF 9 сделан важный шаг - появился компонент VCF Operations Fleet Management. Это не просто переименование - продукт получил улучшенную функциональность, управление обновлениями и версиями стало более "streamlined", то есть рациональным и оптимизированным, а также появился акцент на fleet-подход: управление инфраструктурой как "парком платформ".
Fleet Management способен управлять несколькими инстансами VCF, что становится особенно важным для крупных организаций и распределённых инфраструктур. Именно тут виден "архитектурный сдвиг": VCF 9 проектируется не только как платформа для одного частного облака, а как унифицированная экосистема для гибридных и мультиинстанс-сценариев.
Feature transition: замена Workspace ONE Access
Workspace ONE Access удалён -> VCF Identity Broker
Одно из самых "жёстких" изменений — это не ребрендинг, а полная замена компонента. Workspace ONE Access полностью удалён (removed), вместо него введён новый компонент VCF Identity Broker. Это новый компонент для управления идентификацией (identity management), интеграции доступа, IAM-сценариев (identity access management), интеграции авторизации/аутентификации для экосистемы VCF.
Миграция и перемещение рабочих нагрузок: HCX теперь - часть Operations
VMware HCX -> VCF Operations HCX
HCX остаётся инструментом для пакетной миграции виртуальных машин (bulk migration) и миграций из одной локации в другую (в т.ч. удалённые площадки). Но в VCF 9 меняется позиционирование продукта: он теперь полностью интегрирован в VCF Operations и называется VCF Operations HCX. То есть HCX становится частью единого "операционного" контура VCF 9.
Автоматизация: упрощение названий и интеграция компонентов
Aria Automation -> VCF Automation
Это компонент автоматизации, отвечающий за сценарии и рабочие процессы частного облака, развертывание рабочих нагрузок и ежедневные операции. В VCF 9 это просто VCF Automation.
Orchestrator используется для end-to-end рабочих процессов и автоматизации процессов создания ВМ и операций. В VCF 9 это теперь просто VCF Operations Orchestrator. Это важно: Orchestrator закрепляется как часть "operations-логики", а не просто автономный компонент автоматизации.
VMware Cloud Director: интеграция/поглощение в VCF Automation
Теперь VMware Cloud Director имеет новое позиционирование: продукт полностью интегрирован в VCF Automation. То есть Cloud Director как самостоятельное наименование уходит на второй план, а функции “переезжают” или связываются с модулем VCF Automation.
Слой Kubernetes: vSphere with Tanzu -> vSphere Supervisor
vSphere with Tanzu переименован в vSphere Supervisor
Это важное изменение, отражающее стратегию VCF по треку modern apps. Supervisor рассматривается как компонент для приложений новой волны, перехода monolith > microservices, контейнерного слоя и инфраструктуры enterprise-grade Kubernetes.
Платформа VCF при этом описывается как:
Unified Cloud Platform
Подходит для частного облака
Интегрируется с hyperscalers (AWS, Azure, Google Cloud и т.д.)
Поддерживает enterprise Kubernetes services
Итоги: что означает переход VCF 5 -> VCF 9 для архитектуры и миграции
Переход от VCF 5.x к VCF 9 — это комбинация трёх больших тенденций:
1) Унификация бренда и операционной модели
Aria-компоненты массово становятся частью семейства VCF Operations.
2) Улучшение управления жизненным циклом
LCM эволюционирует в Fleet Management, что отражает переход к управлению группами платформ и множественными VCF-инстансами.
3) Feature transitions (замены функций и ролей компонентов)
Самое заметное — удаление Workspace ONE Access и введение VCF Identity Broker.
Cоответствие компонентов VCF 5.x и VCF 9
SDDC Manager -> SDDC Manager (улучшен)
Aria Operations -> VCF Operations
Aria Operations for Logs -> VCF Operations for Logs
Aria Operations for Network Insights -> VCF Operations for Network
Aria LCM -> VCF Operations Fleet Management
Workspace ONE Access -> VCF Identity Broker (замена продукта)
В новом видео на канале Gnan Cloud Garage подробно разобраны ключевые отличия между VMware Cloud Foundation (VCF) версии 5.2 и VCF 9.0, причем автор подчеркивает: речь идёт не о простом обновлении, а о кардинальной архитектурной переработке платформы.
VCF — это флагманская платформа частного облака от компании VMware, объединяющая вычисления, сеть, хранилище, безопасность, автоматизацию и управление жизненным циклом в едином программно-определяемом стеке. В версии 9.0 VMware делает шаг в сторону «облачного» подхода, ориентированного на масштаб, автоматизацию и гибкость.
Основные отличия VCF 5.2 и VCF 9.0
1. Модель развертывания
VCF 5.2: установка строилась вокруг SDDC Manager и требовала загрузки Cloud Builder размером около 20 ГБ. Развёртывание компонентов происходило последовательно.
VCF 9.0: представлен новый VCF Installer (~2 ГБ) и fleet-based модель. Это обеспечивает более быстрое развертывание, модульную архитектуру и гибкость с первого дня.
Результат: ускорение внедрения и переход от монолитного подхода к модульному.
2. Управление жизненным циклом (LCM)
VCF 5.2: весь LCM был сосредоточен в SDDC Manager.
VCF 9.0: управление разделено между Fleet Management Appliance и SDDC Manager.
Fleet Management отвечает за операции, автоматизацию и управление идентификацией.
SDDC Manager фокусируется на базовой инфраструктуре.
Результат: параллельные обновления, меньшее время простоя и более точный контроль.
3. Управление идентификацией
VCF 5.2: использовались Enhanced Linked Mode и vCenter Identity.
VCF 9.0: внедрены VCF Single Sign-On и VCF Identity Broker, обеспечивающие единую систему идентификации для всех компонентов.
Результат: действительно унифицированная и современная модель identity management.
4. Лицензирование
VCF 5.2: традиционные лицензии — по продуктам и ключам (vSphere, NSX, vSAN, Aria).
VCF 9.0: keyless subscription model — без ключей, с подпиской.
Результат: упрощённое соответствие требованиям, обновления и соответствие современным облачным моделям потребления.
VCF 9.0: операции встроены по умолчанию, обеспечивая fleet-wide мониторинг и compliance «из коробки».
6. Автоматизация
VCF 5.2: автоматизация была дополнительной опцией.
VCF 9.0: решение VCF Automation встроено и оптимизировано для:
AI-нагрузок
Kubernetes
виртуальных машин
Результат: платформа самообслуживания, полностью готовая для разработчиков.
7. Сеть
VCF 5.2: NSX — опциональный компонент.
VCF 9.0: NSX становится обязательным для management и workload-доменов.
Результат: единая программно-определяемая сетевая архитектура во всей среде VCF.
8. Хранилище
VCF 5.2: поддержка vSAN, NFS и Fibre Channel SAN.
VCF 9.0: акцент на vSAN ESA (Express Storage Architecture) и Original Storage Architecture, с планами по расширению поддержки внешних хранилищ.
Результат: фундамент для более современной и производительной storage-архитектуры.
9. Безопасность и соответствие требованиям
VCF 5.2: ручное управление сертификатами и патчами.
VCF 9.0: встроенные средства управления:
унифицированное управление ключами
live patching
secure-by-default подход
Результат: серьёзная модернизация безопасности и Zero Trust по умолчанию.
10. Модель обновлений
VCF 5.2: последовательные апгрейды.
VCF 9.0: параллельные обновления с учётом fleet-aware LCM.
Результат: меньше простоев и лучшая предсказуемость обслуживания.
11. Kubernetes и контейнеры
VCF 5.2: ограниченная поддержка Tanzu.
VCF 9.0: нативный Kubernetes через VCF Automation.
Результат: единая платформа для VM и Kubernetes — полноценная application platform.
12. Импорт существующих сред
VCF 5.2: импорт существующих vSphere/vCenter не поддерживался.
VCF 9.0: можно импортировать существующие окружения как management или workload-домены.
Результат: упрощённая миграция legacy-нагрузок в современное частное облако.
Итог
VCF 5.2 — это классическая платформа частного облака с опциональными возможностями, ну а VCF 9.0 — это современное, cloud-like частное и гибридное облако, ориентированное на масштабирование, автоматизацию и управление флотом инфраструктуры.
Как подчёркивает автор видео, VCF 9.0 — это не апгрейд, а полноценный редизайн, нацеленный на лучший пользовательский опыт и соответствие требованиям современных enterprise и облачных сред.
Brock Peterson написал полезную статью о том, что в новой версии VMware VCF Operations 9 была представлена функция под названием Log Assist (ранее это было частью решения Slyline), которая позволяет загружать пакеты поддержки (Support Bundles) в службу поддержки Broadcom непосредственно из VCF Operations. Вот как это работает.
Во-первых, необходимо зарегистрировать и лицензировать ваш экземпляр VCF Operations. Документацию о том, как это сделать, можно найти здесь.
Во-вторых, в вашей среде должен быть развернут Unified Cloud Proxy. Ранее автор уже рассказывал о том, как его развернуть, здесь. Обязательно убедитесь, что функция Log Assist активирована на вашем Unified Cloud Proxy.
В-третьих, необходимо назначить компоненты Unified Cloud Proxy в разделе Infrastructure Operations > Configurations > Logs > Log Assist Assignment:
Вы можете видеть, что автор назначил свой vCenter и экземпляр VCF Operations. Перетащите компоненты с правой панели в левую:
После назначения они будут отображаться на вкладке Assigned Objects.
Теперь вы можете использовать функцию Log Assist, которая находится в разделе Infrastructure > Diagnostic Findings. Пользователи также могут найти эту функцию в разделе Administration > Control Panel > Log Assist.
Нажмите LOG ASSIST в правом верхнем углу:
Нажмите PREPARE A TRANSFER:
Теперь у вас есть возможность выбрать объект, для которого вы хотите собрать пакет поддержки (Support Bundle). В данном случае веберем vCenter и нажмем NEXT внизу:
Когда статус изменится на Connected, нажмите NEXT:
Введите идентификатор вашего обращения в службу поддержки и выберите TRANSFER:
Вы увидите вашу самую последнюю отправку (Transfer) вверху списка. Нажав на двойную стрелку слева, вы сможете просмотреть детали:
Как вы можете видеть, вместе с пакетом поддержки (Support Bundle) загружается диагностический отчет (Diagnostic Report). После завершения это будет выглядеть вот так:
Ваш пакет журналов поддержки (Support Bundle) теперь загружен в службу поддержки Broadcom для анализа. Также существует подробная статья базы знаний (KB) по этому процессу, вы можете найти её здесь.
Решение VMware vSAN довольно часто всплывает в обсуждениях Memory Tiering — как из-за сходства между этими технологиями, так и из-за вопросов совместимости, поэтому давайте разберёмся подробнее.
Когда мы только начали работать с Memory Tiering, сходство между Memory Tiering и vSAN OSA было достаточно очевидным. Обе технологии используют многоуровневый подход, при котором активные данные размещаются на быстрых устройствах, а неактивные — на более дешёвых, что помогает снизить TCO и уменьшить потребность в дорогих устройствах для хранения «холодных» данных. Обе также глубоко интегрированы в vSphere и просты в реализации. Однако, помимо сходств, изначально возникала некоторая путаница относительно совместимости, интеграции и возможности одновременного использования обеих функций. Поэтому давайте попробуем ответить на эти вопросы.
Да, вы можете одновременно использовать vSAN и Memory Tiering в одних и тех же кластерах. Путаница в основном связана с идеей предоставления хранилища vSAN для Memory Tiering — а это категорически не поддерживается. Мы говорили об этом ранее, но ещё раз подчеркнем: хотя обе технологии могут использовать NVMe-устройства, это не означает, что они могут совместно использовать одни и те же ресурсы. Memory Tiering требует собственного физического или логического устройства, предназначенного исключительно для выделения памяти. Мы не хотим делить это физическое/логическое устройство с чем-либо ещё, включая vSAN или другие датасторы. Почему? Потому что в случае совместного использования мы будем конкурировать за пропускную способность, а уж точно не хотим замедлять работу памяти ради того, чтобы «не тратить впустую» NVMe-пространство. Это всё равно что сказать: "У меня бак машины наполовину пуст, поэтому я залью туда воду, чтобы не терять место".
При этом технически вы можете создать несколько разделов для лабораторной среды (на свой страх и риск), но когда речь идёт о продуктивных нагрузках, обязательно используйте выделенное физическое или логическое (HW RAID) устройство исключительно для Memory Tiering.
Подводя итог по vSAN и Memory Tiering: они МОГУТ сосуществовать, но не могут совместно использовать ресурсы (диски/датасторы). Они хорошо работают в одном кластере, но их функции не пересекаются — это независимые решения. Виртуальные машины могут одновременно использовать датастор vSAN и ресурсы Memory Tiering. Вы даже можете иметь ВМ с шифрованием vSAN и шифрованием Memory Tiering — но эти механизмы работают на разных уровнях. Несмотря на кажущееся сходство, решения функционируют независимо друг от друга и при этом отлично дополняют друг друга, обеспечивая более целостную инфраструктуру в рамках VCF.
Соображения по хранению данных
Теперь мы знаем, что нельзя использовать vSAN для предоставления хранилища для Memory Tiering, но тот же принцип применяется и к другим датасторам или решениям NAS/SAN. Для Memory Tiering требуется выделенное устройство, локально подключённое к хосту, на котором не должно быть создано никаких других разделов. Соответственно, не нужно предоставлять датастор на базе NVMe для использования в Memory Tiering.
Говоря о других вариантах хранения, также важно подчеркнуть, что мы не делим устройства между локальным хранилищем и Memory Tiering. Это означает, что одно и то же устройство не может одновременно обслуживать локальное хранилище (локальный датастор) и Memory Tiering. Однако такие устройства всё же можно использовать для Memory Tiering. Поясним.
Предположим, вы действительно хотите внедрить Memory Tiering в своей среде, но у вас нет свободных NVMe-устройств, и запрос на капитальные затраты (CapEx) на покупку новых устройств не был одобрен. В этом случае вы можете изъять NVMe-устройства из локальных датасторов или даже из vSAN и использовать их для Memory Tiering, следуя корректной процедуре:
Убедитесь, что рассматриваемое устройство входит в рекомендуемый список и имеет класс износостойкости D и класс производительности F или G (см. нашу статью тут).
Удалите NVMe-устройство из vSAN или локального датастора.
Удалите все оставшиеся разделы после использования в vSAN или локальном датасторе.
Создайте раздел для Memory Tiering.
Настройте Memory Tiering на хосте или кластере.
Как вы видите, мы можем «позаимствовать» устройства для нужд Memory Tiering, однако крайне важно убедиться, что вы можете позволить себе потерю этих устройств для прежних датасторов, а также что выбранное устройство соответствует требованиям по износостойкости, производительности и наличию «чистых» разделов. Кроме того, при необходимости обязательно защитите или перенесите данные в другое место на время использования устройств.
Это лишь один из шагов, к которому можно прибегнуть в сложной ситуации, когда необходимо получить устройства; однако если данные на этих устройствах должны сохраниться, убедитесь, что у вас есть свободное пространство в другом месте. Выполняйте эти действия на свой страх и риск.
На момент выхода VCF 9 в процессе развёртывания VCF отсутствует отдельный рабочий процесс для выделения устройств под Memory Tiering, а vSAN автоматически захватывает устройства во время развёртывания. Поэтому при развертывании VCF «с нуля» (greenfield) вам может потребоваться использовать описанную процедуру, чтобы вернуть из vSAN устройство, предназначенное для Memory Tiering. VMware работает над улучшением этого процесса и поменяет его в ближайшем будущем.
VMware Cloud Foundation (VCF) 9.0 предоставляет быстрый и простой способ развертывания частного облака. Хотя обновление с VCF 5.x спроектировано как максимально упрощённое, оно вносит обязательные изменения в методы управления и требует аккуратного, поэтапного выполнения.
Недавно Джонатан Макдональд провёл насыщенный вебинар вместе с Брентом Дугласом, где они подробно разобрали процесс обновления с VCF 5.2 до VCF 9.0. Сотни участников и шквал вопросов ясно показали, что этот переход сейчас волнует многих клиентов VMware.
Джонатан отфильтровал повторяющиеся вопросы, объединив похожие в единые, комплексные темы. Ниже представлены 10 ключевых вопросов («must-know»), заданных аудиторией, вместе с подробными ответами, которые помогут вам уверенно пройти путь к VCF 9.0.
Вопрос 1: Как VMware SDDC Manager выполняет обновления? Есть ли значительные изменения в обновлениях версии 9.0?
Было много вопросов, связанных с SDDC Manager и процессом обновлений. Существенных изменений в том, как выполняются обновления, нет. Если вы знакомы с VCF 5.2, то асинхронный механизм патчинга встроен в консоль точно так же и в версии 9.0. Это позволяет планировать обновления и патчи по необходимости. Главное отличие заключается в том, что интерфейс SDDC Manager был интегрирован в консоль VCF Operations и теперь находится в разделе управления парком (Fleet Management). Многие рабочие процессы также были перенесены, что позволило консолидировать интерфейсы.
Вопрос 2: Есть ли особенности обновления кластеров VMware vSAN Original Storage Architecture (OSA)?
vSAN OSA не «уходит» и не объявлен устаревшим в VCF 9.0. Аппаратные требования для vSAN Express Storage Architecture (ESA) существенно отличаются и могут быть несовместимы с существующим оборудованием. vSAN OSA — отличный способ продолжать эффективно использовать имеющееся оборудование без необходимости покупать новое. Для самого обновления важно проверить совместимость аппаратного обеспечения и прошивок с версией 9.0. Если они поддерживаются, обновление пройдёт так же, как и в предыдущих релизах.
Вопрос 3: Как выполняется обновление VMware NSX?
При обновлении VCF все компоненты, включая NSX, обновляются последовательно. Обычно процесс начинается с компонентов VCF Operations. После этого управление передаётся рабочим процессам SDDC Manager: сначала обновляется сам SDDC Manager, затем NSX, потом VMware vCenter и в конце — хосты VMware ESX.
Вопрос 4: Если VMware Aria Suite развернут в режиме VCF-aware в версии 5.2, нужно ли отвязывать Aria Suite перед обновлением?
Нет. Вы можете сначала обновить компоненты Aria Suite до версии, совместимой с VCF 9, а затем продолжить обновление остальных компонентов.
Вопрос 5: Можно ли обновиться с VCF 5.2 без настроенных LCM и Aria Suite?
Да. Наличие компонентов Aria Suite до обновления на VCF 9.0 не требуется. Однако в рамках обновления будут развернуты Aria Lifecycle (в версии 9.0 — VCF Fleet Management) и VCF Operations, так как они являются обязательными компонентами в 9.0.
Вопрос 6: Сколько хостов допускается в консолидированном дизайне VCF 9.0?
Для нового консолидированного дизайна рекомендуется минимум четыре хоста. При конвергенции инфраструктуры с использованием vSAN требуется минимум три ESX-хоста (четыре рекомендуются для отказоустойчивости). При использовании внешних систем хранения достаточно минимум двух хостов. Что касается максимальных значений, документированных ограничений нет, кроме ограничений VMware vSphere: 96 хостов на кластер и 2500 хостов на один vCenter. В целом рекомендуется по мере роста добавлять дополнительные домены рабочих нагрузок или кластеры для логического разделения среды с точки зрения производительности, доступности и восстановления.
Вопрос 7: Как перейти с VMware Identity Manager (vIDM) на VCF Identity Broker (VIDB) в VCF 9?
Прямого пути обновления или миграции с vIDM на VIDB не существует. Требуется «чистое» (greenfield) развертывание VIDB. Это особенно актуально, если используется VCF Automation, так как в этом случае новое развертывание VIDB является обязательным.
Вопрос 8: Нужно ли загружать дистрибутивы для VCF Operations и куда их помещать?
Это зависит от используемого сценария. В общем случае, если вы выполняете обновление и компоненты Aria ещё не установлены, потребуется загрузить и развернуть виртуальные машины VCF Operations и VCF Operations Fleet Management. После их развертывания бинарные файлы загружаются в репозиторий (depot) VCF Operations Fleet Management для установки дополнительных компонентов. Если вы конвергируете vSphere в VCF, все недостающие компоненты будут развернуты установщиком VCF, и, соответственно, должны быть загружены в него заранее.
Вопрос 9: Существует ли путь отката (rollback), если во время обновления возникла ошибка?
В целом не существует «кнопки отката» для всего VCF сразу. Лучше рассматривать каждое последовательное обновление как контрольную точку. Например, перед обновлением SDDC Manager с 5.2 до 9.0 нужно всегда делать резервную копию. Если во время обновления возникает сбой, можно откатиться к состоянию до ошибки и продолжить диагностику. То же самое относится к другим компонентам. При сбоях в обновлении NSX, vCenter или ESX-хостов нужно оценить ситуацию и либо выполнить откат, либо обратиться в поддержку, если время окна обслуживания истекает и необходимо срочно восстановить работоспособность среды. Именно поэтому тщательное планирование имеет решающее значение при любом обновлении VCF.
Вопрос 10: Существует ли путь миграции с VMware Cloud Director (VCD) на VCF Automation?
На данный момент VCD не поддерживается в VCF 9.0, и официальных путей миграции не существует. Если у вас есть вопросы по этому поводу, обратитесь к вашему Account Director.
Диаграмма задержек VMware Cloud Foundation 9.0 теперь официально доступна на сайте Ports and Protocols в разделе Network Diagrams > VMware Cloud Foundation. Это официальный и авторитетный источник, который наглядно показывает сетевые взаимодействия и требования к задержкам в VCF 9.0.
Данное руководство настоятельно рекомендуется распечатать и разместить на рабочем месте каждого архитектора и администратора. Оно значительно упрощает проектирование, внедрение и сопровождение инфраструктуры, помогает быстрее выявлять узкие места, а также служит удобной шпаргалкой при обсуждении архитектурных решений, устранении неполадок и проверке соответствия требованиям. Фактически, это must-have материал для всех, кто работает с VMware Cloud Foundation в производственной среде.
Диаграмма демонстрирует, как различные элементы инфраструктуры VCF — управляющие домены, рабочие домены и центральные службы — взаимодействуют друг с другом в рамках распределённой частной облачной платформы, а также какие целевые значения Round-Trip Time (RTT) рекомендованы для стабильной и предсказуемой работы.
Что отражено на диаграмме:
VCF Fleet Components: диаграмма охватывает два отдельных экземпляра VCF (Instance 1 и Instance 2), включая их управляющие домены (Management Domain) и рабочие домены (Workload Domain), а также центральные Fleet-сервисы — VCF Operations и VCF Automation.
Целевые задержки: на диаграмме проставлены ориентировочные максимальные RTT-значения между компонентами, например между коллекторами VCF Operations и такими элементами, как vCenter, SDDC Manager, NSX Manager и ESX-хостами. Это служит практическим ориентиром для сетевых инженеров при планировании WAN- или LAN-связей между локациями.
Линии связи разной направленности: взаимодействия выполняются по разным путям и цветам, отражая направление обмена данными и зависимости между сервисами. Это помогает визуализировать, какие службы должны быть ближе друг к другу с точки зрения сети, а какие могут находиться дальше.
Практическая ценность
Такой сетевой ориентир крайне полезен архитекторам и администраторам, которые проектируют либо оптимизируют VCF-окружения в распределённых инфраструктурах. Он служит чёткой справочной картой, позволяющей:
Определить, какие связи нужно обеспечить минимально короткими с точки зрения задержки.
Согласовать проектные требования к ширине канала и RTT в разных сегментах сети.
Избежать узких мест в межкластерных коммуникациях, которые могут повлиять на производительность, управление или репликацию данных.
Диаграмма — это не просто техническая схема, а полноценный план качества сети, который должен учитываться при разворачивании VCF 9.0 на уровне предприятия.
Broadcom в сотрудничестве с Dell, Intel, NVIDIA и SuperMicro недавно продемонстрировала преимущества виртуализации, представив результаты MLPerf Inference v5.1. Платформа VMware Cloud Foundation (VCF) 9.0 показала производительность, сопоставимую с bare metal, по ключевым AI-бенчмаркам, включая Speech-to-Text (Whisper), Text-to-Video (Stable Diffusion XL), большие языковые модели (Llama 3.1-405B и Llama 2-70B), графовые нейронные сети (R-GAT) и компьютерное зрение (RetinaNet). Эти результаты были достигнуты как на GPU-, так и на CPU-решениях с использованием виртуализированных конфигураций NVIDIA с 8x H200 GPU, GPU 8x B200 в режиме passthrough/DirectPath I/O, а также виртуализированных двухсокетных процессоров Intel Xeon 6787P.
Для прямого сравнения соответствующих метрик смотрите официальные результаты MLCommons Inference 5.1. Этими результатами Broadcom вновь демонстрирует, что виртуализованные среды VCF обеспечивают производительность на уровне bare metal, позволяя заказчикам получать преимущества в виде повышенной гибкости, доступности и адаптивности, которые предоставляет VCF, при сохранении отличной производительности.
VMware Private AI — это архитектурный подход, который балансирует бизнес-выгоды от AI с требованиями организации к конфиденциальности и соответствию нормативам. Основанный на ведущей в отрасли платформе частного облака VMware Cloud Foundation (VCF), этот подход обеспечивает конфиденциальность и контроль данных, выбор между решениями с открытым исходным кодом и коммерческими AI-платформами, а также оптимальные затраты, производительность и соответствие требованиям.
Private AI позволяет предприятиям использовать широкий спектр AI-решений в своей среде — NVIDIA, AMD, Intel, проекты сообщества с открытым исходным кодом и независимых поставщиков программного обеспечения. С VMware Private AI компании могут развертывать решения с уверенностью, зная, что Broadcom выстроила партнерства с ведущими поставщиками AI-технологий. Broadcom добавляет мощь своих партнеров — Dell, Intel, NVIDIA и SuperMicro — в VCF, упрощая управление дата-центрами с AI-ускорением и обеспечивая эффективную разработку и выполнение приложений для ресурсоемких AI/ML-нагрузок.
В тестировании были показаны три конфигурации в VCF:
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC с NVLink-соединенными 8x B200 в режиме DirectPath I/O
Dell PowerEdge XE9680 с NVLink-соединенными 8x H200 в режиме vGPU
Конфигурация 1-node-2S-GNR_86C_ESXi_172VCPU-VM с процессорами Intel® Xeon® 6787P с 86 ядрами.
Производительность MLPerf Inference 5.1 с VCF на сервере SuperMicro с NVIDIA 8x B200
VCF поддерживает как DirectPath I/O, так и технологии NVIDIA Virtual GPU (vGPU) для использования GPU в задачах AI и других GPU-ориентированных нагрузках. Для демонстрации AI-производительности с GPU NVIDIA B200 был выбран DirectPath I/O для бенчмаркинга MLPerf Inference.
Инженеры запускали нагрузки MLPerf Inference на сервере SuperMicro SuperServer AS-4126GS-NBR-LCC с восемью GPU NVIDIA SXM B200 с 180 ГБ HBM3e при использовании VCF 9.0.0.
В таблице ниже показаны аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на bare metal и виртуализированных системах. Бенчмарки были оптимизированы с помощью NVIDIA TensorRT-LLM. TensorRT-LLM включает в себя компилятор глубокого обучения TensorRT и содержит оптимизированные ядра, этапы пред- и пост-обработки, а также примитивы меж-GPU и межузлового взаимодействия, обеспечивая выдающуюся производительность на GPU NVIDIA.
Параметр
Bare Metal
Виртуальная среда
Система
SuperMicro GPU SuperServer SYS-422GA-NBRT-LCC
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC
Процессоры
2x Intel Xeon 6960P, 72 ядра
2x AMD EPYC 9965, 192 ядра
Логические процессоры
144
192 из 384 (50%) выделены виртуальной машине для инференса (при загрузке CPU менее 10%). Таким образом, 192 остаются доступными для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
GPU
8x NVIDIA B200, 180 ГБ HBM3e
DirectPath I/O, 8x NVIDIA B200, 180 ГБ HBM3e
Межсоединение ускорителей
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
Память
2,3 ТБ
Память хоста — 3 ТБ, 2,5 ТБ выделено виртуальной машине для инференса
Хранилище
4x NVMe SSD по 15,36 ТБ
4x NVMe SSD по 13,97 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.9 и драйвер 575.57.08
CUDA 12.8 и драйвер 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
Сравнение производительности виртуализованных и bare metal ML/AI-нагрузок на примере сервера SuperMicro SuperServer AS-4126GS-NBR-LCC:
Некоторые моменты:
Результат сценария Llama 3.1 405B в интерактивном режиме не был верифицирован Ассоциацией MLCommons. Broadcom и SuperMicro не отправляли его на проверку, поскольку это не требовалось.
Результаты Stable Diffusion XL, представленные Broadcom и SuperMicro, не могли быть напрямую сопоставлены с результатами SuperMicro на том же оборудовании, поскольку SuperMicro не отправляла результаты бенчмарка Stable Diffusion на платформе bare metal. Поэтому сравнение выполнено с другой заявкой, использующей сопоставимый хост с 8x NVIDIA B200-SXM-180GB.
Рисунок выше показывает, что AI/ML-нагрузки инференса из различных доменов — LLM (Llama 3.1 с 405 млрд параметров), Speech-to-Text (Whisper от OpenAI) и Text-to-Image (Stable Diffusion XL) — в VCF достигают производительности, сопоставимой с bare metal. При запуске AI/ML-нагрузок в VCF пользователи получают преимущества управления датацентром, предоставляемые VCF, при сохранении производительности на уровне bare metal.
Производительность MLPerf Inference 5.1 с VCF на сервере Dell с NVIDIA 8x H200
Broadcom поддерживает корпоративных заказчиков, использующих AI-инфраструктуру от различных аппаратных вендоров. В рамках раунда заявок для MLPerf Inference 5.1, VMware совместно с NVIDIA и Dell продемонстрировала VCF 9.0 как отличную платформу для AI-нагрузок, особенно для генеративного AI. Для бенчмаркинга был выбран режим vGPU, чтобы показать еще один вариант развертывания, доступный заказчикам в VCF 9.0.
Функциональность vGPU, интегрированная с VCF, предоставляет ряд преимуществ для развертывания и управления AI-инфраструктурой. Во-первых, VCF формирует группы устройств из 2, 4 или 8 GPU с использованием NVLink и NVSwitch. Эти группы могут выделяться различным виртуальным машинам, обеспечивая гибкость распределения GPU-ресурсов в соответствии с требованиями нагрузок и повышая утилизацию GPU.
Во-вторых, vGPU позволяет нескольким виртуальным машинам совместно использовать GPU-ресурсы на одном хосте. Каждой ВМ выделяется часть памяти GPU и/или вычислительных ресурсов GPU в соответствии с профилем vGPU. Это дает возможность нескольким небольшим нагрузкам совместно использовать один GPU, исходя из их требований к памяти и вычислениям, что повышает плотность консолидации, максимизирует использование ресурсов и снижает затраты на развертывание AI-инфраструктуры.
В-третьих, vGPU обеспечивает гибкое управление дата-центрами с GPU, поддерживая приостановку/возобновление работы виртуальных машин и VMware vMotion (примечание: vMotion поддерживается только в том случае, если AI-нагрузки не используют функцию Unified Virtual Memory GPU).
И наконец, vGPU позволяет различным GPU-ориентированным нагрузкам (таким как AI, графика или другие высокопроизводительные вычисления) совместно использовать одни и те же физические GPU, при этом каждая нагрузка может быть развернута в отдельной гостевой операционной системе и принадлежать разным арендаторам в мультиарендной среде.
VMware запускала нагрузки MLPerf Inference 5.1 на сервере Dell PowerEdge XE9680 с восемью GPU NVIDIA SXM H200 с 141 ГБ HBM3e при использовании VCF 9.0.0. Виртуальным машинам в тестах была выделена лишь часть ресурсов bare metal. В таблице ниже представлены аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на системах bare metal и в виртуализированной среде.
Аппаратное и программное обеспечение для Dell PowerEdge XE9680:
Параметр
Bare Metal
Виртуальная среда
Система
Dell PowerEdge XE9680
Dell PowerEdge XE9680
Процессоры
Intel Xeon Platinum 8568Y+, 96 ядер
Intel Xeon Platinum 8568Y+, 96 ядер
Логические процессоры
192
Всего 192, 48 (25%) выделены виртуальной машине для инференса, 144 доступны для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
Память хоста — 3 ТБ, 2 ТБ (67%) выделено виртуальной машине для инференса
Хранилище
2 ТБ SSD, 5 ТБ CIFS
2x SSD по 3,5 ТБ, 1x SSD на 7 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.8 и драйвер 570.133
CUDA 12.8 и драйвер Linux 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
Результаты MLPerf Inference 5.1, представленные в таблице, демонстрируют высокую производительность для больших языковых моделей (Llama 3.1 405B и Llama 2 70B), а также для задач генерации изображений (SDXL — Stable Diffusion).
Результаты MLPerf Inference 5.1 при использовании 8x vGPU в VCF 9.0 на аппаратной платформе Dell PowerEdge XE9680 с 8x GPU NVIDIA H200:
Бенчмарки
Пропускная способность
Llama 3.1 405B Server (токенов/с)
277
Llama 3.1 405B Offline (токенов/с)
547
Llama 2 70B Server (токенов/с)
33 385
Llama 2 70B Offline (токенов/с)
34 301
Llama 2 70B — высокая точность — Server (токенов/с)
33 371
Llama 2 70B — высокая точность — Offline (токенов/с)
34 486
SDXL Server (сэмплов/с)
17,95
SDXL Offline (сэмплов/с)
18,64
На рисунке ниже сравниваются результаты MLPerf Inference 5.1 в VCF с результатами Dell на bare metal на том же сервере Dell PowerEdge XE9680 с GPU H200. Результаты как Broadcom, так и Dell находятся в открытом доступе на сайте MLCommons. Поскольку Dell представила только результаты для Llama 2 70B, на рисунке 2 показано сравнение производительности MLPerf Inference 5.1 в VCF 9.0 и на bare metal именно для этих нагрузок. Диаграмма демонстрирует, что разница в производительности между VCF и bare metal составляет всего 1–2%.
Сравнение производительности виртуализированных и bare metal ML/AI-нагрузок на Dell XE9680 с 8x GPU H200 SXM 141 ГБ:
Производительность MLPerf Inference 5.1 в VCF с процессорами Intel Xeon 6-го поколения
Intel и Broadcom совместно продемонстрировали возможности VCF, ориентированные на заказчиков, использующих исключительно процессоры Intel Xeon со встроенным ускорением AMX для AI-нагрузок. В тестах запускали нагрузки MLPerf Inference 5.1, включая Llama 3.1 8B, DLRM-V2, R-GAT, Whisper и RetinaNet, на системе, представленной в таблице ниже.
Аппаратное и программное обеспечение для систем Intel
AI-нагрузки, особенно модели меньшего размера, могут эффективно выполняться на процессорах Intel Xeon с ускорением AMX в среде VCF, достигая производительности, близкой к bare metal, и одновременно получая преимущества управляемости и гибкости VCF. Это делает процессоры Intel Xeon отличной отправной точкой для организаций, начинающих свой путь в области AI, поскольку они могут использовать уже имеющуюся инфраструктуру.
Результаты MLPerf Inference 5.1 при использовании процессоров Intel Xeon в VCF показывают производительность на уровне bare metal. В сценариях, где в датацентре отсутствуют ускорители, такие как GPU, или когда AI-нагрузки менее вычислительно требовательны, в зависимости от задач заказчика, AI/ML-нагрузки могут быть развернуты на процессорах Intel Xeon в VCF с преимуществами виртуализации и при сохранении производительности на уровне bare metal, как показано на рисунке ниже:
Бенчмарки MLPerf Inference
Каждый бенчмарк определяется набором данных (Dataset) и целевым уровнем качества (Quality Target). В следующей таблице приведено краткое описание бенчмарков, входящих в данную версию набора тестов (официальные правила остаются первоисточником):
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему (SUT) в самом начале прогона. В сценарии Server LoadGen отправляет новые запросы в SUT в соответствии с распределением Пуассона. Это показано в таблице ниже.
Сценарии тестирования MLPerf Inference:
Сценарий
Генерация запросов
Длительность
Сэмплов на запрос
Ограничение по задержке
Tail latency
Метрика производительности
Server
LoadGen отправляет новые запросы в SUT согласно распределению Пуассона
270 336 запросов и 60 секунд
1
Зависит от бенчмарка
99%
Максимально поддерживаемый параметр пропускной способности Пуассона
VCF предоставляет заказчикам несколько гибких вариантов развертывания AI-инфраструктуры, поддерживает оборудование от различных вендоров и позволяет использовать разные подходы к запуску AI-нагрузок, применяющих как GPU, так и CPU для вычислений.
При использовании GPU виртуализированные конфигурации виртуальных машин в наших бенчмарках задействуют лишь часть ресурсов CPU и памяти, при этом обеспечивая производительность MLPerf Inference 5.1 на уровне bare metal даже при пиковом использовании GPU — это одно из ключевых преимуществ виртуализации. Такой подход позволяет задействовать оставшиеся ресурсы CPU и памяти для выполнения других нагрузок с полной изоляцией, снизить стоимость AI/ML-инфраструктуры и использовать преимущества виртуализации VCF при управлении датацентрами.
Результаты бенчмарков показывают, что VCF 9.0 находится в «зоне Златовласки» для AI/ML-нагрузок, обеспечивая производительность, сопоставимую с bare metal. VCF также упрощает управление и быструю обработку нагрузок благодаря использованию vGPU, гибких NVLink-соединений между устройствами и технологий виртуализации, позволяющих применять AI/ML-инфраструктуру для графики, обучения и инференса. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой, обеспечивая совместное использование дорогостоящих аппаратных ресурсов несколькими арендаторами.
VMware vCenter Converter – это классический инструмент VMware для перевода физических и виртуальных систем в формат виртуальных машин VMware. Его корни уходят к утилите VMware P2V Assistant, которая существовала в 2000-х годах для «Physical-to-Virtual» миграций. В 2007 году VMware выпустила первую версию Converter (3.0), заменив P2V Assistant...
Доступность данных — ключевая компетенция корпоративных систем хранения. На протяжении десятилетий такие системы стремились обеспечить высокий уровень доступности данных при одновременном соблюдении ожиданий по производительности и эффективности использования пространства. Достичь всего этого одновременно непросто.
Кодирование с восстановлением (erasure coding) играет важную роль в хранении данных устойчивым, но при этом эффективным с точки зрения занимаемого пространства способом. Этот пост поможет лучше понять, как erasure coding реализовано в VMware vSAN, чем оно отличается от подходов, применяемых в традиционных системах хранения, и как корректно интерпретировать возможности erasure code в контексте доступности данных.
Назначение Erasure Coding
Основная ответственность любой системы хранения — вернуть запрошенный бит данных. Чтобы делать это надежно, системе хранения необходимо сохранять данные устойчивым способом. Простейшая форма устойчивости данных достигается посредством нескольких копий или «зеркал», которые позволяют поддерживать доступность при возникновении отказа в системе хранения, например при выходе из строя диска в массиве хранения или хоста в распределённой системе хранения, такой как vSAN. Одна из проблем этого подхода — высокая стоимость хранения: полные копии данных занимают много места. Одна дополнительная копия удваивает объём, две — утраивают.
Erasure codes позволяют хранить данные устойчиво, но гораздо более эффективно с точки зрения пространства, чем традиционное зеркалирование. Вместо хранения копий данные распределяются по нескольким локациям — каждая из которых может считаться точкой отказа (например, диск или хост в распределённой системе, такой как vSAN). Фрагменты данных формируют «полосу» (stripe), к которой добавляются фрагменты четности, создаваемые при записи данных. Данные четности получаются в результате математических вычислений. Если какой-либо фрагмент данных отсутствует, система может прочитать доступные части полосы и вычислить недостающий фрагмент, используя четность. Таким образом, она может либо выполнить исходный запрос чтения «на лету», либо реконструировать отсутствующие данные в новое место. Тип erasure code определяет, может ли он выдержать потерю одного, двух или более фрагментов при сохранении доступности данных.
Erasure codes обеспечивают существенную экономию пространства по сравнению с традиционным зеркальным хранением. Экономия зависит от характеристик конкретного типа erasure code — например, сколько отказов он способен выдержать и по скольким локациям распределяются данные.
Erasure codes бывают разных типов. Их обычно обозначают количеством фрагментов данных и количеством фрагментов четности. Например, обозначение 6+3 или 6,3 означает, что полоса состоит из 6 (k) фрагментов данных и 3 (m) фрагментов четности, всего 9 (n) фрагментов. Такой тип erasure code может выдержать отказ любых трёх фрагментов, сохранив доступность данных. Он обеспечивает такую устойчивость при всего лишь 50% дополнительного расхода пространства.
Но erasure codes не лишены недостатков. Операции ввода-вывода становятся более сложными: одна операция записи может преобразовываться в несколько операций чтения и записи, что называют «усилением ввода-вывода» (I/O amplification). Это может замедлять обработку в системе хранения, а также увеличивать нагрузку на CPU и требовать больше полосы пропускания. Однако при правильной реализации erasure codes могут сочетать устойчивость с высокой производительностью. Например, инновационная архитектура vSAN ESA устраняет типичные проблемы производительности erasure codes, и RAID-6 в ESA может обеспечивать такую же или даже лучшую производительность, чем RAID-1.
Хранение данных в vSAN и в традиционном массиве хранения
Прежде чем сравнивать erasure codes в vSAN и традиционных системах хранения, рассмотрим, как vSAN хранит данные по сравнению с классическим массивом.
Хранилища часто предоставляют большой пул ресурсов в виде LUN. В контексте vSphere он форматируется как datastore с VMware VMFS, где располагаются несколько виртуальных машин. Команды SCSI передаются от ВМ через хосты vSphere в систему хранения. Такой datastore на массиве охватывает большое количество устройств хранения в его корпусе, что означает не только широкую логическую границу (кластерная файловая система с множеством ВМ), но и большую физическую границу (несколько дисков). Как и многие другие файловые системы, такая кластерная ФС должна оставаться целостной, со всеми метаданными и данными, доступными в полном объёме.
vSAN использует совершенно иной подход. Вместо классической файловой системы с большой логической областью данных, распределённой по всем хостам, vSAN оперирует малой логической областью данных для каждого объекта. Примерами могут служить диски VMDK виртуальной машины, постоянный том для контейнера или файловый ресурс, предоставленный службами файлов vSAN. Именно это делает vSAN аналогичным объектному хранилищу, даже несмотря на то, что фактически это блочное хранилище с использованием SCSI-семантики или файловой семантики в случае файловых сервисов. Для дополнительной информации об объектах и компонентах vSAN см. пост «vSAN Objects and Components Revisited».
Такой подход обеспечивает vSAN целый ряд технических преимуществ по сравнению с монолитной кластерной файловой системой в традиционном массиве хранения. Erasure codes применяются к объектам независимо и более гранулярно. Это позволяет заказчикам проектировать кластеры vSAN так, как они считают нужным — будь то стандартный односайтовый кластер, кластер с доменами отказа для отказоустойчивости на уровне стоек или растянутый кластер (stretched cluster). Кроме того, такой подход позволяет vSAN масштабироваться способами, недоступными при традиционных архитектурных решениях.
Сравнение erasure coding в vSAN и традиционных системах хранения
Имея базовое понимание того, как традиционные массивы и vSAN предоставляют ресурсы хранения, рассмотрим, чем их подходы к erasure coding отличаются. В этих сравнениях предполагается наличие одновременных отказов, поскольку многие системы хранения способны справляться с единичными отказами в течение некоторого времени.
Массив хранения (Storage Array)
В данном примере традиционный массив использует erasure code конфигурации 22+3 для одного LUN (k=22, m=3, n=25).
Преимущества:
Относительно низкие накладные расходы по ёмкости. Дополнительная ёмкость, потребляемая данными четности для поддержания доступности при сбоях в доменах отказа (устройствах хранения), составляет около 14%. Такого низкого уровня удаётся достичь благодаря распределению данных по очень большому числу устройств хранения.
Относительно высокий уровень отказоустойчивости (3). Любые три устройства хранения могут выйти из строя, и том останется доступным. Но, как отмечено ниже, это только часть картины.
Компромиссы:
Относительно большой «радиус поражения». Если число отказов превысит то, на которое рассчитан массив, зона воздействия будет очень большой. В некоторых случаях может пострадать весь массив.
Защита только от отказов устройств хранения. Erasure coding в массивах защищает только от отказов самих накопителей. Массивы могут испытывать серьёзную деградацию производительности и доступности при других типах отказов, например, межсоединений (interconnects), контроллеров хранения и некорректных обновлениях прошивок. Ни один erasure code не может обеспечить доступность данных, если выйдёт из строя больше контроллеров, чем массив способен выдержать.
Относительно высокий эффект на производительность во время или после отказов. Отказы при больших значениях k и m могут требовать очень много ресурсов на восстановление и быть более подвержены высоким значениям tail latency.
Относительно большое количество потенциальных точек отказа на одну четность. Соотношение 8,33:1 отражает высокий показатель потенциальных точек отказа относительно количества битов четности, обеспечивающих доступность. Высокое соотношение указывает на более высокую хрупкость.
Последний пункт является чрезвычайно важным. Erasure codes нельзя оценивать только по заявленному уровню устойчивости (m), но необходимо учитывать сопоставление заявленной устойчивости с количеством потенциальных точек отказа, которые она прикрывает (n). Это обеспечивает более корректный подход к пониманию вероятностной надёжности системы хранения.
vSAN
В этом примере предположим, что у нас есть кластер vSAN из 24 хостов, и объект данных ВМ настроен на использование RAID-6 erasure code ы (k=4, m=2, n=6).
Важно отметить, что компоненты, формирующие объект vSAN при использовании RAID-6, будут содержать как фрагменты данных, так и фрагменты четности. Как описывает Христос Караманолис в статье "The Use of Erasure Coding in vSAN" (vSAN OSA, примерно 2018 год), vSAN не создаёт отдельные компоненты четности.
Преимущества:
Относительно небольшой «радиус поражения». Если кластер переживает более двух одновременных отказов хостов, это затронет лишь некоторые объекты, но не выведет из строя весь datastore.
Защита от широкого спектра типов отказов. Erasure coding в vSAN учитывает отказы отдельных устройств хранения, хостов и отказы заранее определённых доменов (например, стоек).
Относительно низкое влияние на производительность во время или после отказа. Небольшие значения k уменьшают вычислительные затраты при восстановлении.
Относительно малое число потенциальных точек отказа на единицу четности. Соотношение 3:1 указывает на малое количество возможных точек отказа по сравнению с числом битов четности, обеспечивающих доступность.
Компромиссы:
Низкая абсолютная устойчивость объекта к отказам (2). У vSAN RAID-6 (4+2) заявленная устойчивость меньше. Однако важно помнить:
граница отказа — это объект, а не весь кластер, количество потенциальных точек отказа на четность существенно ниже.
Относительно более высокие накладные расходы. Дополнительная ёмкость, потребляемая битами четности для поддержания доступности при отказе домена (хоста), составляет 50%.
Несмотря на то, что RAID-6 в vSAN защищает от 2 отказов (в отличие от 3), он остаётся чрезвычайно надёжным благодаря небольшому количеству потенциальных точек отказа: всего 6 против 25. Это обеспечивает vSAN RAID-6 (4+2) техническое преимущество перед схемой хранения массива 22+3, если сравнивать надёжность с точки зрения вероятностей отказов.
Для vSAN использование erasure code с малым значением n обеспечивает гораздо большую гибкость в построении кластеров под самые разные сценарии. Например, RAID-6 (4+2) можно использовать минимум на 6 хостах. Для erasure code 22+3 теоретически потребовалось бы не менее 25 хостов в одном кластере.
Развязка размера кластера и доступности
RAID-6 в vSAN всегда остаётся схемой 4+2, независимо от размера кластера. Когда к объекту применяется политика хранения FTT=2 с RAID-6, это означает, что объект может выдержать два одновременных отказа хостов, на которых находятся его компоненты.
Это свойство относится к состоянию объекта, а не всего кластера. Отказы на других хостах не влияют на доступность данного объекта, за исключением того, что эти хосты могут быть использованы для восстановления недостающей части полосы с помощью четности.
vSAN рассматривает такие уцелевшие хосты как кандидатов для размещения реконструируемых компонентов, чтобы вернуть объекту заданный уровень устойчивости.
Такой подход позволяет vSAN разорвать зависимость между размером кластера и уровнем доступности. В то время как многие масштабируемые системы хранения становятся более хрупкими по мере увеличения числа узлов, подход vSAN, напротив, снижает риски по мере масштабирования кластера.
Для дополнительной информации о доступности и механизмах обработки отказов в vSAN см. документ "vSAN Availability Technologies" на VMware Resource Center.
Итог
Erasure coding — это мощная технология, позволяющая хранить данные очень устойчиво и при этом эффективно использовать пространство. Но не все erasure codes одинаково полезны.
vSAN использует такие схемы erasure coding, которые обеспечивают оптимальный баланс устойчивости, гибкости и эффективности использования пространства в распределённой среде. В сочетании с дополнительными механизмами оптимизации пространства — такими как сжатие данных в vSAN и глобальная дедупликация в ESA (в составе VCF 9.0), хранилище vSAN становится ещё более производительным, ёмким и надёжным, чем когда-либо.
Дункан Эппинг выпустил обзорное видео, где он отвечает на вопрос одного из читателей, который касается поведения VMware vSAN после восстановления отказавших площадок. Речь идёт о сценарии, когда производится Site Takeover и два сайта выходят из строя, а позже снова становятся доступными. Что же происходит с виртуальными машинами и их компонентами в такой ситуации?
Автор решил смоделировать следующий сценарий:
Отключить preferred-локацию и witness-узел.
Выполнить Site Takeover, чтобы виртуальная машина Photon-1 стала снова доступна после ее перезапуска, но уже только на оставшейся рабочей площадке.
После восстановления всех узлов проверить, как vSAN автоматически перераспределит компоненты виртуальной машины.
Поведение виртуальной машины после отказа
Когда preferred-локация и witness отключены, виртуальная машина Photon-1 продолжает работу благодаря механизму vSphere HA. Компоненты ВМ в этот момент существуют только на вторичном домене отказа (fault domain), то есть на той площадке, которая осталась доступной.
Автор пропускает часть сценария с перезапуском ВМ, поскольку этот процесс уже подробно освещался ранее.
Что происходит при восстановлении сайтов
После того как preferred-локация и witness возвращаются в строй, начинается полностью автоматический процесс:
vSAN анализирует политику хранения, назначенную виртуальной машине.
Поскольку политика предусматривает растяжение ВМ между двумя площадками, система автоматически начинает перераспределение компонентов.
Компоненты виртуальной машины снова создаются и на preferred-локации, и на secondary-локации.
При этом администратору не нужно предпринимать никаких действий — все операции происходят автоматически.
Важный момент: полная ресинхронизация
Дункан подчёркивает, что восстановление не является частичным, а выполняется полный ресинк данных:
Компоненты, которые находились на preferred-локации до сбоя, vSAN считает недействительными и отбрасывает.
Данные перезапущенной ВМ полностью синхронизируются с рабочей площадки (теперь это secondary FD) на вновь доступную preferred-локацию.
Это необходимо для исключения расхождений и гарантии целостности данных.
Итоги
Демонстрация показывает, что vSAN при восстановлении площадок:
Автоматически перераспределяет компоненты виртуальных машин согласно политике хранения.
Выполняет полную ресинхронизацию данных.
Не требует ручного вмешательства администратора.
Таким образом, механизм stretched-кластеров vSAN обеспечивает предсказуемое и безопасное восстановление после крупных сбоев.
В Broadcom сосредоточены на том, чтобы помочь клиентам модернизировать инфраструктуру, повысить устойчивость и упростить операции — без добавления сложности для команд, которые всем этим управляют. За последние несколько месяцев было выпущено несколько обновлений, делающих облако VMware Cloud on AWS (VMC) более гибким и простым в использовании. Легко пропустить последние обновления в последних примечаниях к релизам, поэтому мы хотим рассказать о некоторых из самых свежих функций.
Последние обновления предоставляют корпоративным клиентам более экономичную устойчивость благодаря нестандартным вторичным кластерам (non-stretched secondary clusters) и улучшенным возможностям масштабирования вниз, более прозрачную операционную информацию благодаря обновлённому пользовательскому интерфейсу, улучшенный VMC Sizer, новые Host Usage API, а также продолжающиеся улучшения продукта HCX 4.11.3.
Оптимизация развертываний SDDC: улучшения для stretched-кластеров
Когда вы развертываете Software Defined Datacenter (SDDC) в VMC, вам предоставляется выбор между стандартным развертыванием и stretched-развертыванием. Стандартный кластер развертывается в одной зоне доступности AWS (AZ), тогда как stretched-кластер обеспечивает повышенную доступность, развертывая SDDC в трёх зонах доступности AWS. Две зоны используются для размещения экземпляров, а третья — для компонента vSAN Witness.
Поскольку SDDC в stretched-кластерах размещает хосты в двух зонах доступности AWS, клиентам необходимо планировать ресурсы по схеме два к одному, что может быть слишком дорого для рабочих нагрузок, которые не требуют высокой доступности. Кроме того, если stretched-кластер масштабируется более чем до шести хостов, ранее его нельзя было уменьшить обратно. Чтобы улучшить обе эти ситуации, команда VMC внедрила нестандартные вторичные кластеры (Non-Stretched Secondary Clusters) в stretched-SDDC, а также улучшенные возможности масштабирования вниз для stretched-кластеров.
Нестандартные вторичные кластеры в stretched-SDDC
Ранее все кластеры в stretched-SDDC были растянуты между двумя зонами доступности. В этом обновлении только первичный кластер должен быть stretched, в то время как вторичные кластеры теперь могут развертываться в одной зоне доступности.
В stretched-кластере хосты должны развертываться равномерно, поэтому минимальный шаг масштабирования — два хоста.
Но в нестандартном вторичном кластере можно добавлять хосты по одному, что позволяет увеличивать количество развернутых хостов только в той зоне доступности AWS, где они действительно нужны.
Некоторые ключевые преимущества:
Обеспечивает преимущества как stretched-, так и non-stretched-кластеров в одном и том же SDDC.
Позволяет расширять кластер в одной AZ по одному хосту в non-stretched-кластерах.
Снижает стоимость для рабочих нагрузок, которым не требуется доступность stretched-кластера, включая тестовые и/или девелоперские окружения, где высокая доступность не обязательна.
Поддерживает архитектуры приложений с нативной репликацией на уровне приложения — их можно развертывать в двух независимых нестандартных вторичных кластерах (Non-Stretched Secondary Clusters).
VMC поддерживает stretched-кластеры для приложений, которым требуется отказоустойчивость между AZ. Начиная с версии SDDC 1.24 v5, клиенты получают большую гибкость в том, как их кластеры развертываются и масштабируются. Non-stretched-кластеры могут быть развернуты только в одной из двух AWS AZ, в которых находятся stretched-хосты, и эта функция доступна только для SDDC версии 1.24v5 и выше. Кроме того, SLA для non-stretched-кластера отличается от SLA для stretched-кластера, так как non-stretched не предоставляет повышенную доступность.
При планировании новых развертываний SDDC рассмотрите возможность использования Stretched Cluster SDDC, чтобы получить преимущества и высокой доступности, и оптимизированного размещения рабочих нагрузок.
Улучшенные возможности масштабирования вниз (Scale-Down) для stretched-кластеров
Ранее stretched-кластеры нельзя было уменьшить ниже шести хостов (три в каждой AZ). Теперь вы можете уменьшить кластер с шести или более хостов до четырёх хостов (два в каждой AZ) или даже до двух хостов (по одному в каждой AZ), в зависимости от доступных ресурсов и других факторов. Это даёт вам больший контроль над инфраструктурой и помогает оптимизировать расходы.
Ключевые сценарии использования:
Если использование ресурсов рабочей нагрузки снижалось со временем, и теперь вам необходимо уменьшить stretched-кластер, ориентируясь на текущие потребности.
Если ранее вы увеличивали stretched-кластер до шести или более хостов в период пикового спроса, но сейчас такие мощности больше не нужны.
Если вы недавно перевели свои кластеры с i3.metal на i4i.metal или i3en.metal и больше не нуждаетесь в прежнем количестве хостов. Новые типы инстансов обеспечивают такую же или лучшую производительность с меньшим набором хостов, что позволяет экономично уменьшить кластер.
Однако перед уменьшением stretched-кластера необходимо учитывать несколько важных моментов:
Если в вашем первичном кластере используются крупные управляющие модули (large appliances), необходимо поддерживать минимум шесть хостов (три в каждой AZ).
Для кластеров с кастомной конфигурацией 8 CPU минимальный размер — четыре хоста (два в каждой AZ).
Масштабирование вниз невозможно, если кластер уже на пределе ресурсов или если уменьшение нарушило бы пользовательские политики.
Изучите текущую конфигурацию, сравните её с рекомендациями выше — и вы сможете эффективно адаптировать свой stretched-кластер под текущие потребности.
Контролируйте свои данные: новый Host Usage Report API
VMware представила новый Host Usage Report API, который обеспечивает программный доступ к данным о потреблении хостов. Теперь вы можете получать ежедневные отчёты об использовании хостов за любой период и фильтровать их по региону, типу инстанса, SKU и другим параметрам — всё через простой API.
Используйте эти данные, чтобы анализировать тенденции использования хостов, оптимизировать расходы и интегрировать метрики напрямую в существующие инструменты отчётности и дашборды. Host Usage Report API поддерживает стандартные параметры запросов, включая сортировку и фильтрацию, что даёт вам гибкость в получении именно тех данных, которые вам нужны.
Изображение выше — это пример вывода API. Вы можете автоматизировать этот процесс, чтобы передавать данные в любой аналитический инструмент по вашему выбору.
Улучшения продукта: HCX версии 4.11.3 теперь доступен для VMC
Теперь VMware HCX версии 4.11.3 доступен для VMware Cloud on AWS, и он включает важные обновления, о которых вам стоит знать.
Что нового в HCX 4.11.3?
Этот сервисный релиз содержит ключевые исправления и улучшения в областях datapath, системных обновлений и общей эксплуатационной стабильности, чтобы обеспечить более плавную работу. Полный перечень всех улучшений можно найти в официальных HCX Release Notes. Версия HCX 4.11.3 продлевает поддержку до 11 октября 2027 года, обеспечивая долгосрочную стабильность и спокойствие. VMware настоятельно рекомендует всем клиентам обновиться до версии 4.11.3 как можно скорее, так как более старые версии больше не поддерживаются.
Если вы настраиваете HCX впервые, VMware Cloud on AWS автоматически развернёт версию 4.11.3. Для существующих развертываний 4.11.3 теперь является единственной доступной версией для обновления. Нужна помощь, чтобы начать? Ознакомьтесь с инструкциями по активации HCX и по обновлению HCX в VMware Cloud on AWS.
Улучшенный интерфейс: обновлённый VMware Cloud on AWS UI
VMware Cloud on AWS теперь оснащён обновлённым пользовательским интерфейсом с более упрощённой компоновкой, более быстрой навигацией и улучшенной согласованностью на всей платформе. Новый интерфейс уже доступен по адресу https://vmc.broadcom.com.
Улучшенные рекомендации по сайзингу среды: обновления VMC Sizer и Cluster Conversion
VMware представила серьёзные улучшения в процессе конвертации кластеров VMC (VMC Cluster Conversion) в инструменте VMware Cloud Sizer. Эти обновления обеспечивают более точные рекомендации по сайзингу, большую прозрачность и улучшенный пользовательский опыт при планировании перехода с хостов i3.metal на i3en.metal или i4i.metal.
Что нового в оценках VMC Cluster Conversion?
Обновлённый алгоритм оценки в VMC Sizer теперь позволяет получить более полное представление о ваших потребностях в ресурсах перед переходом с i3.metal на более новые типы инстансов.
Рекомендация по количеству хостов в обновлённом выводе VMC Sizer формируется на основе шести ресурсных измерений, и итоговая рекомендация определяется наибольшим из них.
В отчёт включены следующие параметры:
Вычислительные ресурсы (compute)
Память (memory)
Использование хранилища (storage utilization) — с консервативным и агрессивным вариантами оценки
Политики хранения vSAN (vSAN storage policies)
NSX Edge
Другие критически важные параметры
Все эти данные объединены в ясный и практичный отчёт VMC Sizer с рекомендациями, адаптированными под ваш сценарий миграции на новые типы инстансов.
Этот результат оценки является моментальным снимком текущего использования ресурсов и не учитывает будущий рост рабочих нагрузок. При планировании конвертации кластеров следует учитывать и несколько других важных моментов:
Итоговое количество хостов и параметры сайзинга будут подтверждены уже в ходе фактической конвертации кластера.
Клиентам рекомендуется повторно выполнять оценку сайзинга после любых существенных изменений конфигурации, ресурсов или других параметров.
В ходе конвертации политики RAID не изменяются.
Предоставляемые в рамках этого процесса оценки подписки VMware служат исключительно для планирования и не являются гарантированными финальными требованиями.
Фактические потребности в подписке могут оказаться выше предварительных оценок, что может потребовать покупки дополнительных подписок после конвертации.
Возвраты средств или уменьшение объёма подписки не предусмотрены, если предварительная оценка превысит фактические потребности.
В постах ранее мы подчеркивали ценность, которую NVMe Memory Tiering приносит клиентам Broadcom, и то, как это стимулирует ее внедрение. Кто же не хочет сократить свои расходы примерно на 40% просто благодаря переходу на VMware Cloud Foundation 9? Мы также затронули предварительные требования и оборудование в части 1, а архитектуру — в Части 2; так что теперь поговорим о правильном масштабировании вашей среды, чтобы вы могли максимально эффективно использовать свои вложения и одновременно снизить затраты.
Правильное масштабирование для NVMe Memory Tiering касается главным образом оборудования, но здесь есть два возможных подхода: развёртывания greenfield и brownfield.
Начнем с brownfield — внедрения Memory Tiering на существующей инфраструктуре. Вы пришли к осознанию, что VCF 9 — действительно интегрированный продукт, и решили развернуть его, но только что узнали о Memory Tiering. Не волнуйтесь, вы всё ещё можете внедрить NVMe Memory Tiering после развертывания VCF 9. Прочитав части 1 и 2, вы узнали о важности классов производительности и выносливости NVMe, а также о требовании 50% активной памяти. Это означает, что нам нужно рассматривать NVMe-устройство как минимум такого же размера, что и DRAM, поскольку мы удвоим объём доступной памяти. То есть, если каждый хост имеет 1 ТБ DRAM, у нас также должно быть минимум 1 ТБ NVMe. Вроде бы просто. Однако мы можем взять NVMe и покрупнее — и всё равно это будет дешевле, чем покупка дополнительных DIMM. Сейчас объясним.
VMware не случайно транслирует мысль: «покупайте NVMe-устройство как минимум такого же размера, что и DRAM», поскольку по умолчанию они используют соотношение DRAM:NVMe равное 1:1 — половина памяти приходится на DRAM, а половина на NVMe. Однако существуют рабочие нагрузки, которые не слишком активны с точки зрения использования памяти — например, некоторые VDI-нагрузки. Если у вас есть рабочие нагрузки с 10% активной памяти на постоянной основе, вы можете действительно воспользоваться расширенными возможностями NVMe Memory Tiering.
Соотношение 1:1 выбрано по следующей причине: большинство нагрузок хорошо укладывается в такие пропорции. Но это отношение DRAM:NVMe является параметром расширенной конфигурации, который можно изменить — вплоть до 1:4, то есть до 400% дополнительной памяти. Поэтому для рабочих нагрузок с очень низкой активностью памяти соотношение 1:4 может максимизировать вашу выгоду. Как это влияет на стратегию масштабирования?
Отлично, что вы спросили) Поскольку DRAM:NVMe может меняться так же, как меняется активность памяти ваших рабочих нагрузок, это нужно учитывать уже на этапе закупки NVMe-устройств. Вернувшись к предыдущему примеру хоста с 1 ТБ DRAM, вы, например, решили, что 1 ТБ NVMe — разумный минимум, но при нагрузках с очень низкой активной памятью этот 1 ТБ может быть недостаточно выгодным. В таком случае NVMe на 4 ТБ позволит использовать соотношение 1:4 и увеличить объём доступной памяти на 400%. Именно поэтому так важно изучить активную память ваших рабочих нагрузок перед покупкой NVMe-устройств.
Еще один аспект, влияющий на масштабирование, — размер раздела (partition). Когда мы создаём раздел на NVMe перед настройкой NVMe Memory Tiering, мы вводим команду, но обычно не указываем размер вручную — он автоматически создаётся равным размеру диска, но максимум до 4 ТБ. Объём NVMe, который будет использоваться для Memory Tiering, — это комбинация размера раздела NVMe, объёма DRAM и заданного отношения DRAM:NVMe. Допустим, мы хотим максимизировать выгоду и «застраховать» оборудование на будущее, купив 4 ТБ SED NVMe, хотя на хосте всего 1 ТБ DRAM. После настройки вариантами по умолчанию размер раздела составит 4 ТБ (это максимальный поддерживаемый размер), но для Memory Tiering будет использован лишь 1 ТБ NVMe, поскольку используется соотношение 1:1. Если нагрузка изменится или мы поменяем соотношение на, скажем, 1:2, то размер раздела останется прежним (пересоздавать не требуется), но теперь мы будем использовать 2 ТБ NVMe вместо 1 ТБ — просто изменив коэффициент соотношения. Важно понимать, что не рекомендуется менять это соотношение без надлежащего анализа и уверенности, что активная память рабочих нагрузок вписывается в доступный объём DRAM.
DRAM:NVME
DRAM Size
NVMe Partition Size
NVMe Used
1:1
1 TB
4 TB
1 TB
1:2
1 TB
4 TB
2 TB
1:4
1 TB
4 TB
4 TB
Итак, при определении размера NVMe учитывайте максимальный поддерживаемый размер раздела (4 ТБ) и соотношения, которые можно настроить в зависимости от активной памяти ваших рабочих нагрузок. Это не только вопрос стоимости, но и вопрос масштабируемости. Имейте в виду, что даже при использовании крупных NVMe-устройств вы всё равно сэкономите значительную сумму по сравнению с использованием только DRAM.
Теперь давайте поговорим о вариантах развертывания greenfield, когда вы заранее знаете о Memory Tiering и вам нужно закупить серверы — вы можете сразу учесть эту функцию как параметр в расчете стоимости. Те же принципы, что и для brownfield-развертываний, применимы и здесь, но если вы планируете развернуть VCF, логично тщательно изучить, как NVMe Memory Tiering может существенно снизить стоимость покупки серверов. Как уже говорилось, крайне важно убедиться, что ваши рабочие нагрузки подходят для Memory Tiering (большинство подходят), но проверку провести необходимо.
После исследования вы можете принимать решения по оборудованию на основе квалификации рабочих нагрузок. Допустим, все ваши рабочие нагрузки подходят для Memory Tiering, и большинство из них используют около 30% активной памяти. В таком случае всё ещё рекомендуется придерживаться консервативного подхода и масштабировать систему с использованием стандартного соотношения DRAM:NVMe 1:1. То есть, если вам нужно 1 ТБ памяти на хост, вы можете уменьшить объем DRAM до 512 ГБ и добавить 512 ГБ NVMe — это даст вам требуемый общий объем памяти, и вы уверены (благодаря исследованию), что активная память ваших нагрузок всегда уместится в DRAM. Кроме того, количество NVMe-устройств на хост и RAID-контроллер — это отдельное решение, которое не влияет на доступный объем NVMe, поскольку в любом случае необходимо предоставить одно логическое устройство, будет ли это один независимый NVMe или 2+ устройства в RAID-конфигурации. Однако это решение влияет на стоимость и отказоустойчивость.
С другой стороны, вы можете оставить исходный объем DRAM в 1 ТБ и добавить еще 1 ТБ памяти через Memory Tiering. Это позволит использовать более плотные серверы, сократив общее количество серверов, необходимых для размещения ваших нагрузок. В этом случае экономия достигается за счет меньшего количества оборудования и компонентов, а также сокращения затрат на охлаждение и энергопотребление.
В заключение, при определении размеров необходимо учитывать все переменные: объем DRAM, размер NVMe-устройств, размер раздела и соотношение DRAM:NVMe. Помимо этих параметров, для greenfield-развертываний следует проводить более глубокий анализ — именно здесь можно добиться дополнительной экономии, покупая DRAM только для активной памяти, а не для всего пула, как мы делали годами. Говоря о факторах и планировании, стоит также учитывать совместимость Memory Tiering с vSAN — это будет рассмотрено в следующей части серии.
При развертывании Zero Trust для быстрого устранения пробелов в безопасности и улучшения сегментации в существующей (brownfield) или новой (greenfield) среде, клиентам нужен предписывающий многоэтапный рабочий процесс сегментации, разработанный для постепенной защиты восточно-западного трафика в частном облаке VMware Cloud Foundation (VCF)...
vSAN File Services — это встроенная в vSAN опциональная функция, которая позволяет организовать файловые расшаренные ресурсы (файловые шары) прямо «поверх» кластера vSAN. То есть, вместо покупки отдельного NAS-массива или развертывания виртуальных машин-файловых серверов, можно просто включить эту службу на уровне кластера.
После включения vSAN File Services становится возможным предоставить SMB-шары (для Windows-систем) и/или NFS-экспорты (для Linux-систем и cloud-native приложений) прямо из vSAN.
Основные возможности и сильные стороны
Вот ключевые функции и плюсы vSAN File Services:
Возможность / свойство
Что это даёт / когда полезно
Поддержка SMB и NFS (v3 / v4.1)
Можно обслуживать и Windows, и Linux / контейнерные среды. vSAN превращается не только в блочное хранилище для виртуальных машин, но и в файловое для приложений и пользователей.
Файл-сервисы без отдельного «файлера»
Нет нужды покупать, настраивать и поддерживать отдельный NAS или физическое устройство — экономия затрат и упрощение инфраструктуры.
Лёгкость включения и управления (через vSphere Client)
Администратор активирует службу через привычный интерфейс, не требуются отдельные системы управления.
До 500 файловых шар на кластер (и до 100 SMB-шар)
Подходит для сравнительно крупных сред, где нужно много шар для разных подразделений, проектов, контейнеров и другого.
Распределение нагрузки и масштабируемость
Служба развёрнута через набор «протокол-сервисов» (контейнеры / агенты), которые равномерно размещаются по хостам; данные шар распределяются как vSAN-объекты — нагрузка распределена, масштабирование (добавление хостов / дисков) + производительность + отказоустойчивость.
Интегрированная файловая система (VDFS)
Это не просто «виртуальные машины + samba/ganesha» — vSAN использует собственную распределённую FS, оптимизированную для работы как файловое хранилище, с балансировкой, метаданными, шардированием и управлением через vSAN.
Мониторинг, отчёты, квоты, ABE-контроль доступа
Как и для виртуальных машин, для файловых шар есть метрики (IOPS, latency, throughput), отчёты по использованию пространства, возможность задать квоты, ограничить видимость папок через ABE (Access-Based Enumeration) для SMB.
Поддержка небольших кластеров / 2-node / edge / remote sites
Можно применять даже на «граничных» площадках, филиалах, удалённых офисах — где нет смысла ставить полноценный NAS.
Когда / кому это может быть особенно полезно
vSAN File Services может быть выгоден для:
Организаций, которые уже используют vSAN и хотят минимизировать аппаратное разнообразие — делать и виртуальные машины, и файловые шары на одной платформе.
Виртуальных сред (от средних до крупных), где нужно предоставить множество файловых шар для пользователей, виртуальных машин, контейнеров, облачных приложений.
Сценариев с контейнерами / cloud-native приложениями, где требуется RWX (Read-Write-Many) хранилище, общие папки, persistent volumes — все это дают NFS-шары от vSAN.
Удалённых офисов, филиалов, edge / branch-site, где нет смысла ставить отдельное файловое хранилище.
Случаев, когда хочется централизованного управления, мониторинга, политики хранения и квот — чтобы всё хранилище было в рамках одного vSAN-кластера.
Ограничения и моменты, на которые нужно обратить внимание
Нужно учитывать следующие моменты при планировании использования:
Требуется выделить отдельные IP-адреса для контейнеров, которые предоставляют шары, плюс требуется настройка сети (promiscuous mode, forged transmits).
Нельзя использовать одну и ту же шару одновременно и как SMB, и как NFS.
vSAN File Services не предназначен для создания NFS датасторов, на которые будут смонтированы хосты ESXi и запускаться виртуальные машины — только файловые шары для сервисов/гостевых систем.
Если требуется репликация содержимого файловых шар — её нужно организовывать вручную (например, средствами операционной системы или приложений), так как vSAN File Services не предлагает встроенной гео-репликации.
При кастомной и сложной сетевой архитектуре (например, stretched-кластер) — рекомендуется внимательно проектировать размещение контейнеров, IP-адресов, маршрутизации и правил site-affinity.
Технические выводы для администратора vSAN
Если вы уже используете vSAN — vSAN File Services даёт возможность расширить функциональность хранения до полноценного файлового — без дополнительного железа и без отдельного файлера.
Это удобно для унификации: блочное + файловое хранение + облачные/контейнерные нагрузки — всё внутри vSAN.
Управление и мониторинг централизованы: через vSphere Client/vCenter, с известными инструментами, что снижает операционную сложность.
Подходит для «гибридных» сценариев: Windows + Linux + контейнеры, централизованные файлы, общие репозитории, home-директории, данные для приложений.
Можно использовать в небольших и распределённых средах — филиалы, edge, remote-офисы — с минимальным оверхэдом.
VMware повторно представила свои сертификации продвинутого уровня с выпуском трёх новых экзаменов VMware Certified Advanced Professional (VCAP) для VMware Cloud Foundation 9.0. Эти сертификации предназначены для опытных IT-специалистов, которые хотят подтвердить свою экспертизу в проектировании, построении и управлении сложными средами частного облака. Возвращение экзаменов VCAP является важной вехой для специалистов VMware, предлагая чёткий путь для карьерного роста и признания их продвинутых навыков.
Понимание сертификации VCAP
Сертификация VMware Certified Advanced Professional (VCAP) — это престижный квалификационный уровень, который означает глубокое понимание технологий VMware и способность применять эти знания в реальных сценариях. Размещённая выше уровня VMware Certified Professional (VCP), сертификация VCAP предназначена для опытных специалистов, которые уже продемонстрировали прочные базовые знания продуктов и решений VMware. Получение сертификации VCAP демонстрирует приверженность к совершенству и высокий уровень профессионализма в специализированной области технологий VMware.
Новые экзамены VCAP для VMware Cloud Foundation 9.0
С выпуском VMware Cloud Foundation 9.0 VMware представила три новых экзамена VCAP, каждый из которых сосредоточен на критически важном аспекте платформы VCF. Эти экзамены ориентированы на конкретные рабочие роли и наборы навыков, позволяя специалистам специализироваться в областях, которые соответствуют их карьерным целям.
1. VMware Certified Advanced Professional - VMware Cloud Foundation 9.0 vSphere Kubernetes Service (3V0-24.25)
Эта сертификация предназначена для специалистов, работающих с контейнеризированными рабочими нагрузками и современными приложениями. Экзамен подтверждает навыки, необходимые для развертывания, управления и обеспечения безопасности vSphere with Tanzu, что позволяет предоставлять Kubernetes-as-a-Service на платформе VCF. Кандидаты на получение этой сертификации должны иметь практический опыт работы с Kubernetes, контейнерными сетями и хранилищами.
2. VMware Certified Advanced Professional - VMware Cloud Foundation 9.0 Automation (3V0-21.25)
Эта сертификация сосредоточена на возможностях автоматизации и оркестрации VMware Cloud Foundation. Экзамен оценивает способность кандидата проектировать, внедрять и управлять рабочими процессами автоматизации с помощью VMware Aria Automation (ранее vRealize Automation). Эта сертификация идеально подходит для специалистов, которые отвечают за автоматизацию предоставления инфраструктуры и сервисов приложений.
3. VMware Certified Advanced Professional - VMware Cloud Foundation 9.0 Operations (3V0-22.25)
Эта сертификация ориентирована на специалистов, отвечающих за ежедневные операции и управление средой VMware Cloud Foundation. Экзамен охватывает такие темы, как мониторинг производительности, управление ёмкостью, устранение неполадок и управление жизненным циклом. Эта сертификация хорошо подходит для системных администраторов, операторов облака и инженеров по надёжности.
Все три новых экзамена VCAP для VMware Cloud Foundation 9.0 имеют схожий формат и структуру. Экзамены проводятся под наблюдением и доступны через Pearson VUE. Они состоят из 60 вопросов и имеют длительность 135 минут. Типы вопросов разнообразны и могут включать множественный выбор, drag-and-drop и практические лабораторные симуляции, обеспечивая комплексную оценку знаний и навыков кандидата.
Заключение
Возвращение экзаменов VCAP для VMware Cloud Foundation 9.0 предоставляет ценную возможность для специалистов VMware подтвердить свои продвинутые навыки и экспертизу. Эти сертификации являются свидетельством способности работать с новейшими технологиями VMware и являются признанным эталоном качества в отрасли. Получив сертификацию VCAP, специалисты могут улучшить свои карьерные перспективы и продемонстрировать свою приверженность к тому, чтобы оставаться на переднем крае постоянно развивающегося мира облачных вычислений.

 RSS
RSS